
TransformerとはGPTなど広く使われるAIモデルで、もともとは自然言語処理の機械翻訳の分野において提案されたEncoderとDecoderからなる深層学習モデルです。こちらの記事ではTransformerやMulti-Head Attentionに関する詳しい解説をしています。ぜひご覧ください。
-

Transformerとは?世界を変えた深層学習モデルの仕組みをわかりやすく徹底解説
近年のAI技術の急激な発展には「Transformer」という深層学習モデルの存在が大きく関わっている。 この記事では、そのTrasformerについてその仕組みとそれがなぜ組み込まれているかを画像を ...
続きを見る

-
Multi-Head AttentionとScaled Dot-Product Attentionの全て:Transformerの核心を徹底解説
この記事では、Transformerの中心的な役割を果たすMulti-Head Attentionについて解説する。 Transformerのほかの機構の詳細な解説はせず、完全にMult ...
続きを見る

Transformerは「Attention機構」を用いることで、入力系列中の遠距離にある各単語間の関連性を捉えることができます。
このような特性を実現させるのが「Scaled Dot-Product Attention機構」です。
\(n\)単語からなる入力系列の各単語を\(d\)次元のベクトルとして表した\(n \times d\)行列を\(X\)とし、\(X\)の線形変換によりQuery行列、Key行列、Value行列をそれぞれ\(Q=X W_Q, K=X W_K,V=X W_V\)として算出し、Q, Kを使って単語間の類似度を算出し優れた文脈把握能力を獲得できるとされています。(ここで\(W_Q,W_K,W_V \in \mathbb{R}^{d \times d}\)はデータによる学習が可能です)
しかし、この類似度を計算する際に系列長\(n\)の二乗に比例して計算コストがかかるため。長い入力系列中の任意に離れた2単語間の関連性が捉えられるTransformerの利点を十分に発揮できないのです。そこでこの記事では、Transformerの計算量を\(O(n^2)\)から\(O(n)\)に減らす手法を紹介します。
Trasformerの計算量
Original Transformer
系列長を\(n\)として、Scaled Dot-Product Attentionの計算は次の式で行われます。
\(Q,K,V \in \mathbb{R}^{n \times d}\)として、\(\mathbf{q}_i^\top,\mathbf{k}_i^\top,\mathbf{v}_i^\top \in \mathbb{R}^d\)を\(Q,K,V\)の\(i\)行目の横ベクトルとすると、出力される\(n \times d\)の行列\(\text{A}\)の\(i\)行目は次のように表すことができます。
$$
\text{A}(Q, K, V)_i=\sum_{j=1}^n\text{softmax}\left(\frac{\mathbf{q}_i^\top \mathbf{k}_j}{\sqrt{d}}\right)\cdot \mathbf{v}_j^\top=\frac{\sum_{j=1}^n \exp \left(\frac{\mathbf{q}_i^{\top} \mathbf{k}_j}{\sqrt{d}}\right) \cdot \mathbf{v}_j^\top}{\sum_{j=1}^n \exp \left(\frac{\mathbf{q}_i^{\top} \mathbf{k}_j}{\sqrt{d}}\right)}
$$
この計算のコストは\(O(d n^2)\)です(下図)。\(W_Q,W_K\)の最適化を行う際の勾配計算のためAttention Matrix(下図の紫の部分)を保存する必要があるので、\(O(n^2 + nd)\)の記憶域を使用してしまいます。
Scaled Dot-Product Attentionのアーキテクチャとその計算量。図中のオーダー表記は時間計算量
Linear Transformer
\(i\)番目と\(j\)番目の入力単語の関連性を表す類似度関数を\(\text{sim}(\mathbf{q}_i, \mathbf{k}_j)=\exp \left(\frac{\mathbf{q}_i^\top \mathbf{k}_j}{\sqrt{d}}\right)\)\((\mathbb{R}^{2 \times d} \rightarrow \mathbb{R}_{+})\)と定めます。
$$
\text{A}(Q, K, V)_i=\frac{\sum_{j=1}^n \text{sim}\left(\mathbf{q}_i, \mathbf{k}_j\right) \cdot \mathbf{v}_j^\top}{\sum_{j=1}^n \text{sim}\left(\mathbf{q}_i, \mathbf{k}_j\right)}\quad.
$$
このような類似度関数\(\text{sim}\)を\(\text{sim}\left(\mathbf{q}_i, \mathbf{k}_j\right)=\phi(\mathbf{q}_i)^\top \phi(\mathbf{k}_j)\)と分解できる関数\(\phi(x)\)があれば、各\(i,j\)に対して\(\text{sim}\left(\mathbf{q}_i, \mathbf{k}_j\right)\)を計算することなく次のように計算できます。
\begin{align*}
\text{A}(Q, K, V)_i &= \frac{\sum_{j=1}^n \text{sim}\left(\mathbf{q}_i, \mathbf{k}_j\right) \cdot \mathbf{v}_j}{\sum_{j=1}^n \text{sim}\left(\mathbf{q}_i, \mathbf{k}_j\right)} = \frac{\sum_{j=1}^n \phi\left(\mathbf{q}_i\right)^\top \phi\left(\mathbf{k}_j\right) \cdot \mathbf{v}_j^\top}{\sum_{j=1}^n \phi\left(\mathbf{q}_i\right)^\top \phi\left(\mathbf{k}_j\right)} \\
&= \frac{\phi\left(\mathbf{q}_i\right)^\top \sum_{j=1}^n \phi\left(\mathbf{k}_j\right) \cdot \mathbf{v}_j^\top}{\phi\left(\mathbf{q}_i\right)^\top \sum_{j=1}^n \phi\left(\mathbf{k}_j\right)}
\end{align*}
ここで、\(\phi\left(\mathbf{k}_j\right) \cdot \mathbf{v}_j^\top,\phi\left(\mathbf{k}_j\right)\)は\(i\)の計算が含まれないので、事前にその値を計算しておくことができます、\(\phi:\mathbb{R}^d \rightarrow \mathbb{R}^m\)のときその計算量は\(O(ndm)\)となります!(下図)。
Linear Attentionのアーキテクチャとその計算量
類似度関数の再構築
$$
\text{sim}(\mathbf{q}, \mathbf{k})=\exp \left(\frac{\mathbf{q}^\top \mathbf{k}}{\sqrt{d}}\right)=\phi(\mathbf{q})^\top \phi(\mathbf{k})
$$
Original Attentionでの類似度関数\(\text{sim}\)に対応するような関数\(\phi\)のベクトルは無限次元となりますので、\(O(ndm)\)の\(m\)が大きくなり実用上計算することができなくなってしまいます。
従ってSoftmax関数にこだわるのでなく、類似度の定義つまりScaled Dot-Product Attentionの定義を変更し再構築します。
Linear Transformerの勾配
\(\bar{\text{A}}_i=\phi\left(\mathbf{q}_i\right)^\top \sum_{j=1}^n \phi\left(\mathbf{k}_j\right) \cdot \mathbf{v}_j^\top\)と、その誤差関数\(\mathcal{L}\)に関する勾配\(\nabla_{\bar{\text{A}}_j} \mathcal{L}\)が与えられた時、\(\phi(Q_i),\phi(V_i),V_i\)の勾配は次のように導出することができます。
$$
\begin{aligned}
\nabla_{\phi\left(\mathbf{q}_i\right)} \mathcal{L} & =\nabla_{\bar{\text{A}}_i} \mathcal{L}\left(\sum_{j=1}^n \phi\left(\mathbf{k}_j\right) \mathbf{v}_j^\top\right)^\top, \\
\nabla_{\phi\left(\mathbf{k}_i\right)} \mathcal{L} & =\left(\sum_{j=1}^n\phi\left(\mathbf{q}_j\right)\left(\nabla_{\bar{\text{A}}_j} \mathcal{L}\right)^\top\right) \mathbf{v}_i, \\
\nabla_{\mathbf{v}_i} \mathcal{L} & =\left(\sum_{j=1}^n\phi\left(\mathbf{q}_j\right)\left(\nabla_{\bar{\text{A}}_j} \mathcal{L}\right)^\top\right)^\top \phi\left(\mathbf{k}_i\right)
\end{aligned}
$$
この結果から、学習時の勾配計算でも\(O(n)\)で計算されることが分かります。
検証
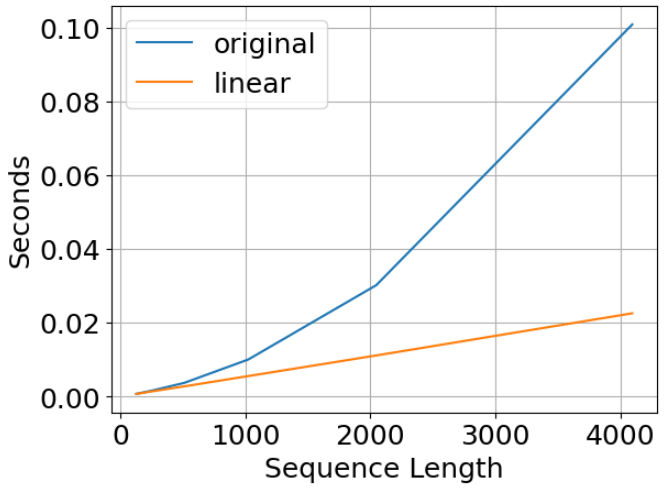
OriginalとLinearの推論速度比較グラフ
Original TransformerとLinear Transformerの系列長に対する推論速度の比較グラフです。縦軸は推論計算時間、横軸は系列長である。Linearは系列の長さに線形に、Originalは二次的にスケールすることがわかります。こちらのGoogle Colabから実行することができます。
ここでは\(\phi(x)=\text{elu}(x)+1\)としています。\(\text{elu}\)関数とは
$$
\text{elu}(x)=\left\{\begin{array}{ll}\alpha\left(e^x-1\right), & x \leq 0 \\ x, & x>0\end{array} \quad(\alpha>0)\right.
$$
というものです。
参考






- BERT Rediscovers the Classical NLP Pipeline[2019][Ian Tenney,Dipanjan Das,Ellie Pavlick]
- Attention is all you need[2017][Vaswani et al.]
- What Does BERT Learn about the Structure of Language?[2019][Genesh Jawahar, Benoit Sagot,Djame,Seddah]
- Approximation and Estimation ability of Transformers for Sequence-to-Sequence Functions with Infinite Dimensional Input[2023][Shokichi Takakura,Taiji Suzuki]
- A Comprehensive Survey on Application of Transformers for Deep Learning Tasks[2023][Saidul Islam et al.]
- Transformer models: an introduction and catalog[2023][Xavier Amatriain]
- Self-Attention with Relative Position Representations[2018][Peter Shaw, Jakob Uszkoreit, Ashish Vaswani]
- Music Transformer[2018][Cheng-Zhi Anna Huang et al.]
- Linearized Relative Positional Encoding[2023][Zhen Qin et al.]
- ON THE RELATIONSHIP BETWEEN SELF-ATTENTION AND CONVOLUTIONAL LAYERS[2019][Jean-Baptiste Cordonnier et al.]
- Transformers are RNNs[2020][Katharopoulos et al.]