
オートエンコーダーの基本概念
オートエンコーダー( Autoencoder )は、入力データをコンパクトな表現(潜在表現)へと圧縮し、その後、圧縮した情報から元のデータを復元することを学習するニューラルネットワークの一種です。具体的には、ある入力ベクトル
$$
\mathbf{x} \in \mathbb{R}^D
$$
を与えると、オートエンコーダーはまずエンコーダ(Encoder)によって \(\mathbf{x}\) を低次元の潜在表現 \(\mathbf{z} \in \mathbb{R}^d へ\) と写像します (ここで通常 \(d \ll D\) とします)。続いて、デコーダ(Decoder)はこの潜在表現 \(\mathbf{z}\) から元の次元に近い空間ヘマッピングし、 \(\hat{\mathbf{x}}\) という再構成を行います。
$$
\hat{\mathbf{x}}=f_{\mathrm{dec}}\left(f_{\mathrm{enc}}(\mathbf{x})\right)
$$
オートエンコーダーは、 \(\mathbf{x}\) と \(\hat{\mathbf{x}}\) の差(再構成誤差)を小さくするように学習します。これにより、潜在空間 \(\mathbf{z}\) が元のデータ構造を保ちつつ本質的特徴を圧縮表現として捉えられると期待されます。
ニューラルネットワークとの関係と多様体仮説
オートエンコーダーは基本的にニューラルネットワークの一種です。エンコーダとデコーダはともにパラメトリックな関数近似器であり、通常、多層パーセプトロン(MLP)や畳み込みニューラルネットワーク(CNN)といったニューラルネットアーキテクチャで実装されます。深層学習の黎明期には、オートエンコーダーは教師なしで特徴抽出器として利用され、後にこの特徴を用いて分類などのタスクを行う「事前学習(pre-training)」が盛んに用いられました。
しかし、なぜわざわざ高次元なデータを低次元へ圧縮しようとするのでしょうか。この根拠の一つとして多様体仮説(Manifold Hypothesis)が挙げられます。多様体仮説とは、「自然界や実社会で得られる高次元データは、そのまま全空間\(\mathbb{R}^D\)に一様に広がっているのではなく、もっと低次元な多様体(可微分な曲がった面や曲線)の近傍に分布している」とする考え方です。たとえば、画像データは画素数が数万次元であっても、実際に自然画像がとりうるパターンはその次元に比べてはるかに制約されています。言い換えれば、実用的なデータは、非常に広大な高次元空間の中で、低次元構造を伴う「島」のような領域に密集して存在する可能性が高いのです。
この多様体仮説により、「高次元データであっても、適切な非線形変換を用いれば、そのデータが内包する本質的自由度( Degrees of Freedom )はずっと少ないはずだ」という期待が成り立ちます。オートエンコーダーは、この潜在的な低次元多様体を学習し、データの分布が潜在空間上でより簡潔な形で表現されるように試みます。
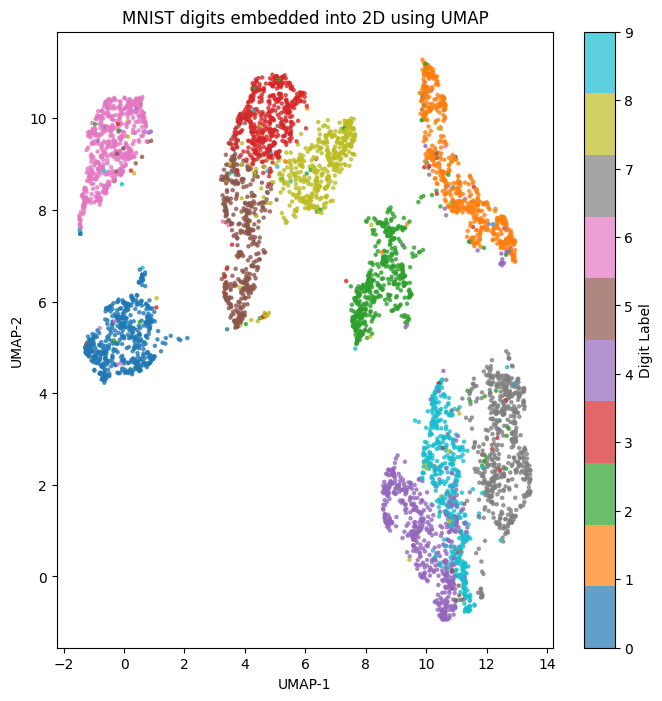
以下に、Pythonとscikit-learnを用いて、多様体仮説を視覚的に感じられるような例として、MNISTデータセット(手書き数字画像)を二次元空間にプロットするコード例を示します。MNISTの手書き数字画像は元々28x28=784次元のピクセルデータであり、本来高次元空間に位置します。しかし、t-SNE(t-Distributed Stochastic Neighbor Embedding)やUMAPといった非線形次元削減手法を用いると、低次元の潜在空間(2次元や3次元)に投影しても、数字ごとにクラスタが自然に形成されることが知られています。これは、多様体仮説、すなわち「高次元データは本質的には低次元の潜在構造(多様体)上に分布している」という考え方を視覚的に裏付ける一例といえます。
以下のコードでは、MNISTデータをロードした後、UMAPライブラリを用いて2次元に写像し、その結果をMatplotlibで可視化します。UMAPを用いることで、t-SNE同様に非線形多様体構造を捉えることができ、同じ数字同士が近くに集まる分布が二次元でも確認できます。
オートエンコーダーの構造
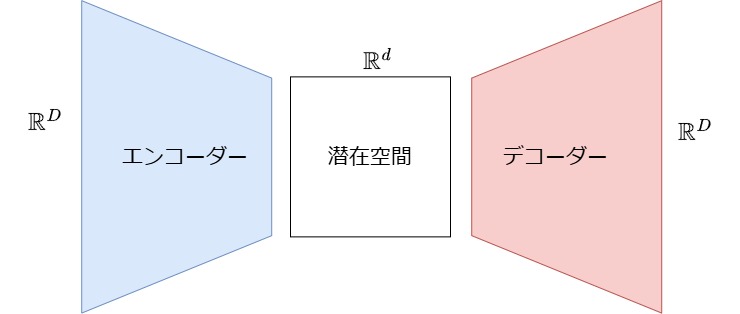
エンコーダ:
エンコーダ \(f_{\mathrm{enc}}: \mathbb{R}^D \rightarrow \mathbb{R}^d\) は高次元入力 \(\mathbf{x}\) を低次元潜在表現 \(\mathbf{z}\) ヘとマッピングします。この変換は非線形関数であり、ニューラルネットワーク層(全結合層、畳み込み層など)と非線形活性化関数 (ReLU、sigmoid、tanhなど)によって構成されます。
エンコーダは、与えられたデータ分布 \(p(\mathbf{x})\) に対して、その背後に潜む低次元構造を学習しようとします。
潜在空間
潜在空間は、データの本質的特徴を低次元で捉える抽象的な空間です。多様体仮説によれば、この潜在空間は元の空間に比べてはるかに次元が小さく、滑らかな多様体上にデータが分布する可能性があります。
潜在空間上では、データを連続的に補間したり、新たな点をサンプリングしたりといった操作が可能になります。つまり、潜在空間はデータの「隠れ構造」を直接扱うための場として機能します
デコーダ
デコーダ \(f_{\mathrm{dec}}: \mathbb{R}^d \rightarrow \mathbb{R}^D\) は潜在表現 \(\mathbf{z}\) から元の高次元空間へのマッピングを実現します。これはエン コーダの逆変換的な役割を持ち、潜在空間で得た表現がどのようなデータを生成するのかを明らかにしま す。
デコーダは、学習済みの潜在構造を用いて、任意の潜在変数 \(\mathbf{z}\) から再構成サンプル \(\hat{\mathbf{x}}\) を生成できるた め、データ生成モデルとしても利用可能です。
多様体仮説による低次元潜在表現の正当化
なぜ潜在空間が低次元であることが重要なのでしょうか。多様体仮説によれば、高次元データは本質的に低次元多様体上に「乗っている」と考えられます。オートエンコーダーは非線形変換を通じて、この多様体構造を明示化します。もしデータが実際にある低次元多様体上にあるなら、エンコーダはその多様体上の座標系を学習し、デコーダはその座標系から高次元空間上への写像を学習することになります。
このように、オートエンコーダーは多様体仮説を暗黙的に利用することで、データの低次元性を引き出し、情報圧縮や特徴抽出を可能にします。
オートエンコーダーの学習プロセスと最適化問題
オートエンコーダーの学習は、入力 \(\mathbf{x}\) と再構成 \(\hat{\mathbf{x}}\) との誤差を最小化する最適化問題として定式化できます。代表的な損失関数は平均二乗誤差(MSE)です。
$$
L(\mathbf{x}, \hat{\mathbf{x}})=\|\mathbf{x}-\hat{\mathbf{x}}\|_2^2
$$
データセット \(\left\{\mathbf{x}_i\right\}_{i=1}^N\) に対して、平均損失を最小化するようパラメータ \(\theta\) (エンコーダ・デコーダのパラメータ集合)を更新します。
$$
\min _\theta \frac{1}{N} \sum_{i=1}^N L\left(\mathbf{x}_i, f_{\mathrm{dec}}\left(f_{\mathrm{enc}}\left(\mathbf{x}_i\right)\right)\right)
$$
この最適化は、勾配降下法やAdamなどの最適化アルゴリズムを用いて行います。学習が進むと、オートエンコーダー は再構成誤差を減らし、潜在空間上に意味のある特徴表現を獲得します。
オートエンコーダーの種類
積層オートエンコーダ (Stacked Autoencoder)
単純なオートエンコーダを多層に積み重ねることで、より表現能力の高い特徴抽出が可能となります。深い層を持つネットワークは、より抽象的な特徴を学習し、多段階の非線形変換を通してデータの本質をより的確に捉えられます。
また、古典的には積層オートエンコーダを用いた事前学習手法(Greedy Layer-wise Pretraining)が、ディープラーニングの性能向上に大きく貢献しました。
畳み込みオートエンコーダ (Convolutional Autoencoder, CAE)
画像データを扱う場合、畳み込みオートエンコーダが有利です。エンコーダは畳み込み層とプーリング層で画像を圧縮し、潜在表現を得ます。デコーダは転置畳み込み層などを用いて元の画像サイズへと復元します。
畳み込み構造は画像上の局所的特徴を活用できるため、高次元の画像データに対して効率的で自然な表現獲得が可能となります。
変分オートエンコーダ (Variational Autoencoder, VAE)
単純なオートエンコーダは再構成をうまく行いますが、潜在空間に明確な確率的解釈を与えていません。 VAEは潜在変数 \(\mathbf{z}\) に事前分布 \(p(\mathbf{z})\) (通常は標準正規分布)を仮定し、エンコーダを潜在変数の事後分布 \(q(\mathbf{z} \mid \mathbf{x})\) を近似するモデルとして学習します。
これにより潜在空間は確率的生成モデルとして明示的に扱え、潜在空間上でのサンプリングを通じて新しいデータ生成が容易になります。
VAEは画像生成モデルにおいて非常に重要な役割を果たすモデルです。
ELBOの導出と理論的背景
確率モデルによるデータ生成と潜在変数の導入
まず、 大局的な問題設定から始めます。深層学習における生成モデルの一つの目標は、観測データX が従う確率分布 \(p(X)\) を学習することです。ここで、
- \(X\) : 観測データ (例えば画像)
- \(p(\cdot)\) : データの生成分布(未知の確率モデル)
とします。
実際の応用では、 \(X\) は高次元かつ複雑で、その確率分布 \(p(X)\) を直接モデル化することは困難です。そこで潜在変数 \(z\) を導入します。潜在変数とは、観測不可能な「隠れた要因」で、これを通じてデータが生成されると考える モデルを「潜在変数モデル」と呼びます。
潜在変数 \(z\) を用いると、観測分布 \(p(X)\) は以下のような積分(周辺化)を通して表現できます。
$$
p(X)=\int p(X, z) d z=\int p(X \mid z) p(z) d z
$$
ここで、
- \(p(z)\) : 潜在変数の事前分布(通常、標準正規分布 \(\mathcal{N}(0, I)\) を仮定)
- \(p(X \mid z)\) : 潜在変数 \(z\) からデータ \(X\) を生成する条件付き分布(デコーダ) とします。
このようなモデルでは、 \(p(X \mid z)\) は「潜在変数 \(z\) を与えたとき、どのようなデータ \(X\) が生じるかりを記述します。実務的には、この \(p(X \mid z)\) をニューラルネットワークでパラメタライズし、 \(z\) を入力として \(X\) の分布(例えば画素値の分布)を出力するモデルとして実装します。
最尤推定とエビデンス(Evidence)
ここで、確率もデル \(p_\theta(X)\) にパラメータ \(\theta\) (ニューラルネットの重みやバイアスなど)を導入すると、データ分布を最も よく説明する \(\theta\) を求めたくなります。これが最尤推定(MLE: Maximum Likelihood Estimation)です。
最尤推定では、観測データ集合 \(\left\{X_i\right\}_{i=1}^N\) に対して、対数尤度
$$
\log p_\theta\left(X_1, X_2, \ldots, X_N\right)=\sum_{i=1}^N \log p_\theta\left(X_i\right)
$$
を最大化します。ここで \(\log p_\theta(X)\) は「エビデンス」と呼ばれ、モデルが観測 \(X\) をどれだけうまく説明できるかを表す重要な指標です。
しかし、この \(\log p_\theta(X)\) は以下のように周辺化積分を含むため、そのままでは扱いが難しい場合がほとんどです。
$$
p_\theta(X)=\int p_\theta(X \mid z) p(z) d z
$$
高次元の積分を直接最適化することは非常に困難です。VAEは、この困難な周辺尤度最大化問題を、変分推論 (Variational Inference)という近似手法を用いて解決します。
変分推論と近似事後分布
本来、潜在変数モデルでの理想は、ベイズの定理に基づく事後分布 \(p_\theta(z \mid X)\) を求めることです。
$$
p_\theta(z \mid X)=\frac{p_\theta(X \mid z) p(z)}{p_\theta(X)}
$$
しかし、 \(p_\theta(X)\) に周辺化積分が入っている以上、これも計算が容易ではありません。そこで、変分推論では、扱い やすい分布族(通常はガウス分布)からなる近似事後分布 \(q_\phi(z \mid X)\) を導入します。
ここで
- \(q_\phi(z \mid X)\) : 潜在変数の近似事後分布
- \(\phi\) : 近似事後分布をパラメタライズするパラメータ(ニュ-ラルネットワークによって、入力 \(X\) から \(\boldsymbol{\mu}(X)\), \(\boldsymbol{\sigma}(X)\) などを出力し、そのガウス分布 \(\mathcal{N}\left(\boldsymbol{\mu}(X), \text{diag}\left(\boldsymbol{\sigma}^2(X)\right)\right)\) を \(q_\phi(z \mid X)\) とする \()\)
VAEでは、この \(q_\phi(z \mid X)\) を「エコーダリと呼び、入カデータ \(X\) から潜在変数分布のパラメータを出力するニューラル ネットワークとして実装します。
エビデンス下界(ELBO)の導出
まず、エビデンス(Evidence) \(\log p_\theta(X)\) を考えます。
1. 潜在変数 \(z\) を導入したモデルでは、
$$
p_\theta(X)=\int p_\theta(X \mid z) p(z) d z
$$
ここで、 \(p_\theta(X \mid z)\) はデコーダモデル、 \(p(z)\) は潜在変数の事前分布(通常は標準正規分布)です。この \(\log p_\theta(X)\) を直接最大化するのは困難です。
2. 任意の分布 \(q_\phi(z \mid X)\) を考え、 \(\log p_\theta(X)\) の式中に1として挿入します。つまり、
$$
1=\frac{q_\phi(z \mid X)}{q_\phi(z \mid X)}
$$
と書けるので、これを積分内部に入れます。
$$
\log p_\theta(X)=\log \int p_\theta(X \mid z) p(z) d z=\log \int q_\phi(z \mid X) \frac{p_\theta(X \mid z) p(z)}{q_\phi(z \mid X)} d z
$$
3. このとき、 \(\frac{p_\theta(X \mid z) p(z)}{q_\phi(z \mid X)}\) は非負関数、 \(q_\phi(z \mid X)\) は確率分布( \(z\) に関する)であり、その期待値として書くこと ができます。
4. イエンセンの不等式( \(\log E[\cdot] \geq E[\log \cdot])\) を用います。
不等式を適用するため、期待値の形に直すと、
$$
\log p_\theta(X)=\log \mathbb{E}_{q_\phi(z \mid X)}\left[\frac{p_\theta(X \mid z) p(z)}{q_\phi(z \mid X)}\right]
$$
ここで、期待値演算子 \(\mathbb{E}_{q_\phi(z \mid X)}[\cdot]\) は「 \(z\) を \(q_\phi(z \mid X)\) からサンプリングしたときの期待値」を意味します。
5. イエンセンの不等式を適用すると、
$$
\log p_\theta(X) \geq \mathbb{E}_{q_\phi(z \mid X)}\left[\log \frac{p_\theta(X \mid z) p(z)}{q_\phi(z \mid X)}\right]
$$
これが変分下界(Variational Lower Bound, ELBO)を導くための主要な不等式です。
6. 次に、右辺の対数分数を和の形に分解します。
$$
\log \frac{p_\theta(X \mid z) p(z)}{q_\phi(z \mid X)}=\log p_\theta(X \mid z)+\log p(z)-\log q_\phi(z \mid X)
$$
よって、
$$
\log p_\theta(X) \geq \mathbb{E}_{q_\phi(z \mid X)}\left[\log p_\theta(X \mid z)+\log p(z)-\log q_\phi(z \mid X)\right]
$$
7. この期待値を3つの部分に分けて書きます。
$$
\log p_\theta(X) \geq \mathbb{E}_{q_\phi(z \mid X)}\left[\log p_\theta(X \mid z)\right]+\mathbb{E}_{q_\phi(z \mid X)}[\log p(z)]-\mathbb{E}_{q_\phi(z \mid X)}\left[\log q_\phi(z \mid X)\right]
$$
8. ここで、KLダイバージェンス( \(D_{\mathrm{KL}}(Q \| P)\) )の定義を思い出します。 KLダイバージェンスは2つの確率分布 \(Q と P\) に対して、
$$
D_{\mathrm{KL}}(Q \| P)=\int Q(z) \log \frac{Q(z)}{P(z)} d z=\mathbb{E}_Q[\log Q(z)]-\mathbb{E}_Q[\log P(z)]
$$
という形で定義され、非負であることが知られています。
9. この定義を用いて、
$$
\mathbb{E}_{q_\phi(z \mid X)}[\log p(z)]-\mathbb{E}_{q_\phi(z \mid X)}\left[\log q_\phi(z \mid X)\right]
$$
の部分をKLダイバージェンスに書き換えることができます。
上記の差を変形します。
$$
\mathbb{E}_{q_\phi(z \mid X)}[\log p(z)]-\mathbb{E}_{q_\phi(z \mid X)}\left[\log q_\phi(z \mid X)\right]=-\left(\mathbb{E}_{q_\phi(z \mid X)}\left[\log q_\phi(z \mid X)\right]-\mathbb{E}_{q_\phi(z \mid X)}[\log p(z)]\right)
$$
この括弧内は、
$$
\mathbb{E}_{q_\phi(z \mid X)}\left[\log q_\phi(z \mid X)\right]-\mathbb{E}_{q_\phi(z \mid X)}[\log p(z)]=D_{\mathrm{KL}}\left(q_\phi(z \mid X) \| p(z)\right)
$$
です。よって、
$$
\mathbb{E}_{q_\phi(z \mid X)}[\log p(z)]-\mathbb{E}_{q_\phi(z \mid X)}\left[\log q_\phi(z \mid X)\right]=-D_{\mathrm{KL}}\left(q_\phi(z \mid X) \| p(z)\right)
$$
10. この結果を元の不等式に代入します。
$$
\log p_\theta(X) \geq \mathbb{E}_{q_\phi(z \mid X)}\left[\log p_\theta(X \mid z)\right]-D_{\mathrm{KL}}\left(q_\phi(z \mid X) \| p(z)\right)
$$
これで、変分下界(Variational Lower Bound)、またはエビデンス下界(ELBO)が得られます。
11. まとめると、
$$
\underbrace{\log p_\theta(X)}_{\text {エビデンス }} \geq \underbrace{\mathbb{E}_{q_\phi(z \mid X)}\left[\log p_\theta(X \mid z)\right]-D_{\mathrm{KL}}\left(q_\phi(z \mid X) \| p(z)\right)}_{\mathcal{L}(\theta, \phi ; X)(\mathrm{ELBO})} .
$$
ELBO \(\mathcal{L}(\theta, \phi ; X)\) は、 \(\log p_\theta(X)\) の下限として機能し、VAEではこのELBOを最大化することで間接的に \(\log p_\theta(X)\) を最大化し、モデルを学習します。
サンプリング操作の微分可能化(Reparameterization Trick)
VAEの学習では、潜在変数 \(\mathbf{z}\) を \(q(\mathbf{z} \mid \mathbf{x})=\mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}(\mathbf{x}), \boldsymbol{\sigma}^2(\mathbf{x}) \mathbf{I}\right)\) からサンプリングしますが、そのま までは勾配計算が困難です。
Reparameterization Trickでは、 \(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\) を固定分布からサンプリングし、
$$
\mathbf{z}=\boldsymbol{\mu}(\mathbf{x})+\boldsymbol{\sigma}(\mathbf{x}) \odot \boldsymbol{\epsilon}
$$
と書き換えます。こうすることで \(\mathbf{z}\) は \(\boldsymbol{\mu}\) と \(\boldsymbol{\sigma}\) の決定的な関数とな以、誤差逆伝播によりパラメータ更新が可能になります。
敵対的オートエンコーダー (Adversarial Autoencoder, AAE)
VAEはKLダイバージェンスで分布整合性を図りますが、AAEはGAN(Generative Adversarial Network)の枠組みを用いて、潜在空間の分布 \(q(\mathbf{z})\) が所望の事前分布 \(p(\mathbf{z})\) に一致するように訓練します。
AAEでは、ディスクリミネーター \(D(\mathbf{z})\) を導入し、 \(D(\mathbf{z})\) は\(\mathbf{z}\)が事前分布由来かエンコーダ由来かを判別し ます。エンコーダはディスクリミネーターを騙すように学習することで、潜在分布を事前分布に近付けます。こ のミニマックスゲームにより、潜在空間の分布が制御可能になります。
AAEはVAEよりも柔軟な分布マッチングを可能とし、潜在空間がより明確な統計的性質を持つことから、生成モデルとして、あるいは教師なし特徴抽出器として有用です。
最適輸送とワッサースタイン距離
確率分布間距離の数理的背景:
分布間距離を測る際、KLダイバージェンスやJSダイバージェンスでは、分布が重ならない場合に有用な勾配が得にくいという問題があります。最適輸送理論は、分布間の「質量移動コスト」に着目し、より滑らかな勾配を提供できるワッサースタイン距離(Wasserstein distance)を定義します。
ワッサースタイン距離の特徴と生成モデルへの応用:
WGAN(Wasserstein GAN)では、損失関数としてワッサースタイン距離の推定値を用いることで、学習の安定化とモード崩壊の軽減を実現しました。オートエンコーダーにおいても、最適輸送距離に基づいた損失関数を導入する研究があり、潜在空間構造のより滑らかな制御や生成品質の向上が期待されています。
オートエンコーダーの応用例
次元削減と潜在表現
高次元データを低次元空間にマッピングすることで、データの可視化や圧縮が可能になります。PCA(主成分分析)などの線形手法よりもオートエンコーダーは非線形構造を捉えやすく、多様体構造をより適切に反映できます。
特徴抽出とクラスタリング
潜在表現はデータの本質的特徴を捉えているため、クラスタリングや分類など下流タスクの前処理として有効です。
ノイズ除去(デノイジングオートエンコーダ)
入力にノイズを付与し、それを取り除くよう訓練したオートエンコーダは、実際のテストデータからノイズを除去する能力を獲得します。これによりロバストな特徴抽出や信号処理への応用が可能です。
データ生成と潜在空間上での操作
VAEやAAEなどの確率的オートエンコーダは、潜在空間上で新たな潜在コード\(\mathbf{z}\)をサンプリングし、それをデコーダで再構成することで新規データサンプルを生成できます。また、潜在空間上で補間を行えば、あるデータから別のデータへ連続的に変形するような創発的な操作も可能です。
オートエンコーダーの利点と課題
利点として、
- 教師なし学習で膨大な未ラベルデータを活用できること
- 非線形次元削減により、複雑なデータ構造を潜在空間で簡潔に記述できること
- 特徴抽出やデータ生成など、多様な応用領域があること
が挙げられます。一方、課題としては
- 適切な潜在次元の選定が難しい
- オートエンコーダーだけで最適な潜在表現が得られる保証はなく、事前分布の仮定やモデル設計が結果に影響する
- 高品質な生成にはデコーダ側の表現能力や学習の安定性が要求される
といった点が指摘できます。また、一般的なオートエンコーダーは潜在空間の「意味的解離(latent disentanglement)」に関して保証がなく、特定の因子(例えば画像中の回転や照明変化)を独立に制御するためには、さらに特殊な手法(β-VAEやFactorVAEなど)が必要です。
参考

https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24#3-vae%E3%81%AE%E7%90%86%E8%AB%96%E7%9A%84%E3%81%AA%E6%A6%82%E8%A6%81