
この記事ではできうる限り厳密にサポートベクターマシンの理論について解説を行っていく。
この記事で解消される疑問一覧
- SVMとは?
- マージンの最大化ってなに?
- 双対問題ってなに?
- KKT条件の使い方?
- カーネル法??
この記事を読めばSVMのおおよそすべてが分かる。
注意としては実装の仕方やコードなどの解説は一切行わない。理論的な部分に関しての解説をとことん行う。
サポートベクターマシン(SVM)とは
サポートベクターマシン(SVM)とは、サポートベクトルマシンとも呼ばれ、分類問題でよく用いられる有名な機械学習の手法の一つである。
分類問題とは、入力されたデータを複数の特定のカテゴリーに分ける問題である。たとえば、写真に写っている動物が犬か猫かを判断する場合、その写真を見て「犬」と「猫」のどちらかのカテゴリーに分類することが分類問題である。
2クラス分類問題は、この分類問題の中でも最も基本的な形であり、入力されたデータを二つのカテゴリー(クラス)のどちらかに分類する問題である。具体的には、データを見てそれが「クラスA」に属するか「クラスB」に属するかを判断する。この「クラスA」と「クラスB」は、問題によって異なる。たとえば、メールが「迷惑メール」か「通常のメール」かを判断する場合、これも2クラス分類問題の一例である。
サポートベクターマシン(SVM)は、この2クラス分類問題を解決するための強力な手法である。SVMは、与えられた入力データをもとに、それがどちらのクラスに属するかを識別する。たとえば、メールの内容を分析して、それが「迷惑メール」か「通常のメール」かを識別する。これを可能にするために、SVMはデータの特徴を分析し、それらを最もうまく分離する境界線(または超平面)を見つけ出す。
このように、2クラス分類問題は機械学習において非常に基本的かつ重要な問題であり、サポートベクターマシンはその解決に非常に有効な手段である。次の節では、サポートベクターマシンがどのようにしてこれを達成するのか、そのメカニズムについて詳しく解説する。
どのようなシーンで使われるのか
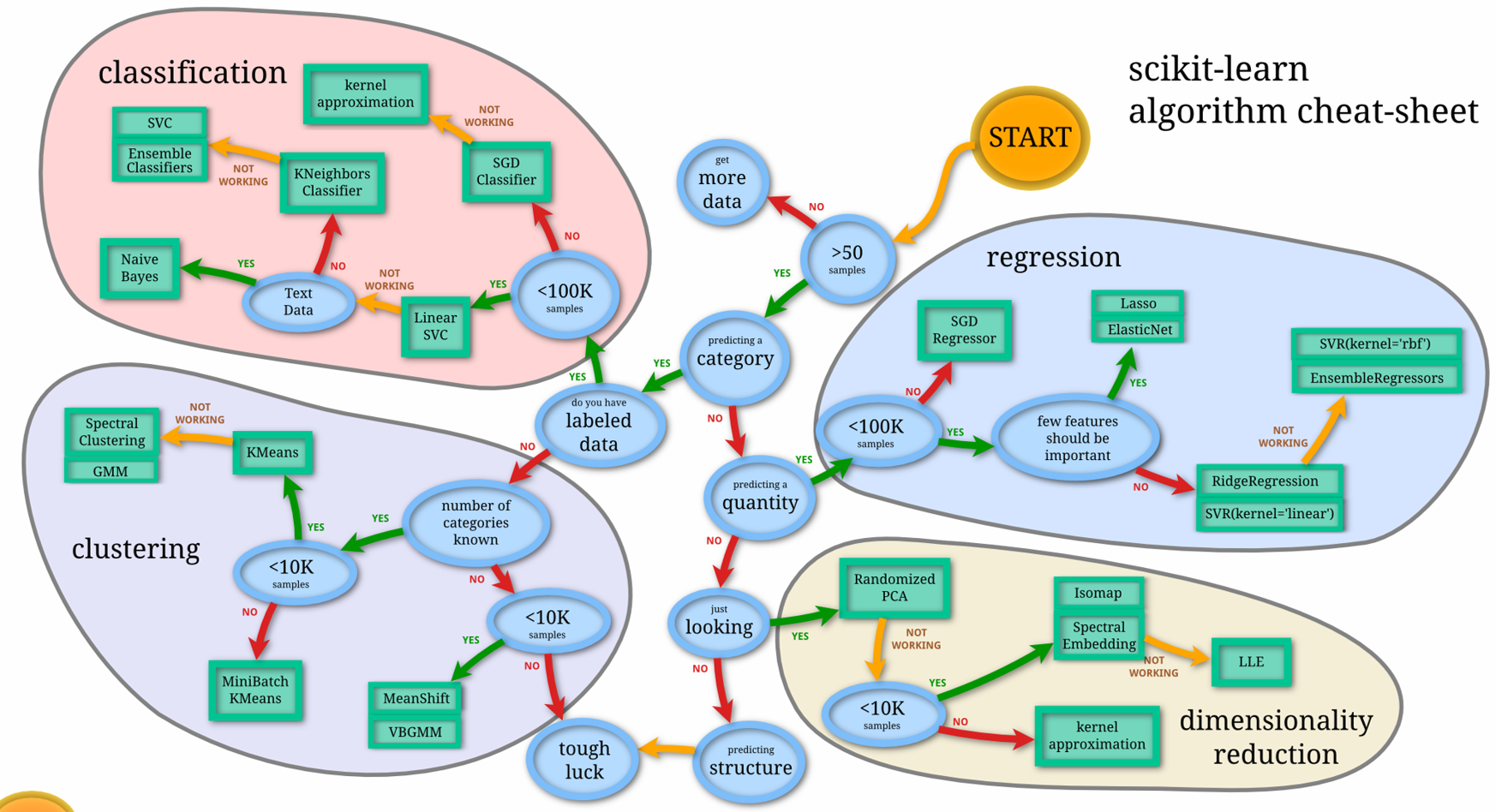
PythonのライブラリであるScikit-learnのチートシートによると、分類問題(classification)において10万以下のサンプル数のデータであればまずは線形SVMを使用し、それがうまくいかなかった場合最終的にアンサンブル学習か非線形のSVMを使用するとある。
つまり、SVMは分類問題の教師ありデータでテキストデータではなく10万サンプル以内の中小規模のデータに対して用いられる。
しかし、実際のところSVMが使われるシーンは多くなく最近ではアンサンブル学習が使われることが多く、特に勾配ブースティングを使ったXGBoostやLightGBMなどのモデルが安定的に高い精度を出力することが多い。
ただ、必ずしもSVMよりもXGBoostやLightGBMが高い精度を出すわけでないので比較をしてみると良い。実際、有名なTitanicのデータを用いてこの三つの手法を比較したが
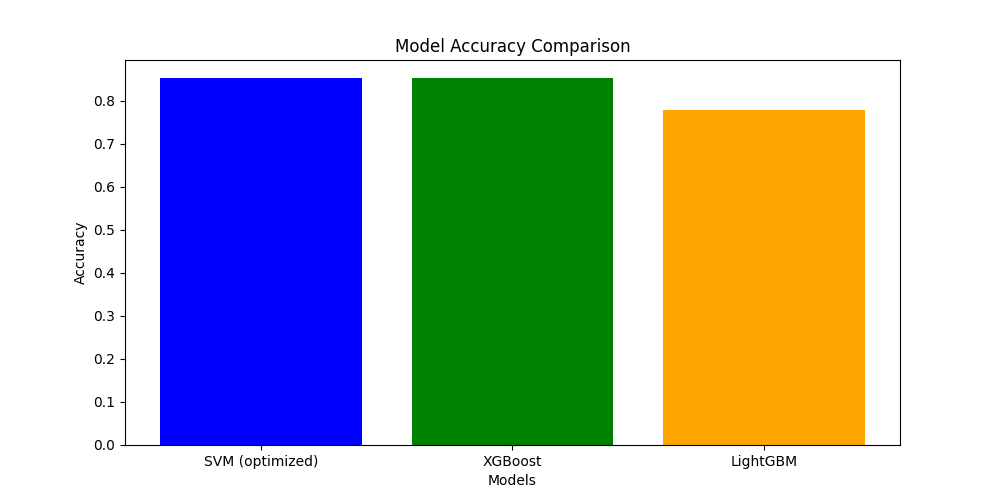
SVMがXGBoostとLightGBMと比べてギリギリだけど最も高い精度を獲得することができた。このように場合によってはアンサンブル学習に勝つ状況もあるので、先に述べた対象が「SVMは分類問題の教師ありデータでテキストデータではなく10万サンプル以内の中小規模のデータ」であるならば一度試してみるのが妥当であると言える。
忙しい人のためのSVMで押さえておくべきこと
これだけ押さえよう!!
- サポートベクトルによるマージン最大化
- カーネル法
サポートベクターマシンってなんだっけ?と思ったらこの二つを思い出しておけばよい。
ここからは理論的な側面を数学的に掘り下げていくので、興味がある人はぜひ追っていってほしい。
ここでは、イメージを掴みやすいので線形SVMによる「サポートベクトルによるマージン最大化」を中心に詳しく解説する。
サポートベクトルによるマージン最大化
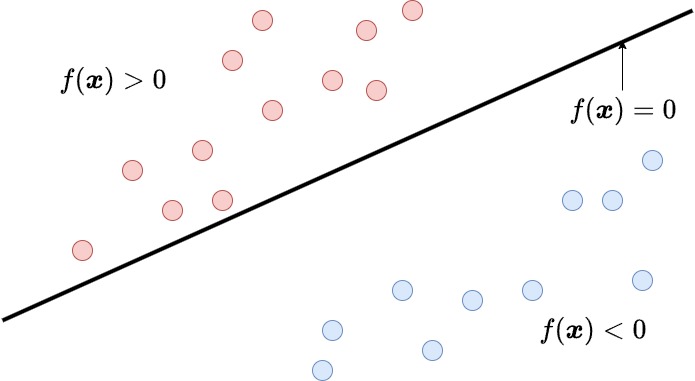
2次元線形分離境界の例、青色と赤い色の丸い点はそれぞれ正のクラスと負のクラスに属する特徴ベクトルとする。SVMの目的はこれを直線\(f(\boldsymbol{x})\)で分離すること
線形SVMの目的は、2クラス分類問題において、データを分離する最適な直線(平面や超平面を含む)を見つけることである。ここでいう「最適な直線」とは、2つのクラスをできるだけきれいに分けることができる直線のことを指す。
訓練集合を考える。この集合は\(n\)個の事例からなり、各事例は\(d\)次元の実数ベクトル\(\boldsymbol{x}_i \in \mathbb{R}^d\)と\(1\)か\(-1\)の値を取るラベル\(y_i \in\{-1,1\}\)から構成される。ここで、自然数\(n\)に対し、\([n]\)は\(1\)から\(n\)までの自然数の集合を表す。
決定関数\(f:\mathbb{R}^d \rightarrow \mathbb{R}\)を用いて、分類器\(g(\boldsymbol{x})\)を定義する。この関数は以下のようになる。
$$
g(x)=\left\{\begin{array}{rl}
1 & f(x)>0 \text { の場合 } \\
-1 & f(x)<0 \text { の場合 }
\end{array}\right.
$$
ここで、\(f(\boldsymbol{x})\)として次の一次関数を考える。
$$
f(\boldsymbol{x})=\boldsymbol{w}^{\top} \boldsymbol{x}+b \tag{1}
$$
この式において、\(\boldsymbol{w} \in \mathbb{R}^d\)は\(d\)次元の実数ベクトルであり、\(b \in \mathbb{R}\)はスカラー変数(バイアスとも呼ばれる)である。これらは事前にはわからない未知の変数であり、これらを推定することが重要となる。
\(g(\boldsymbol{x})\)の定義では、\(f(\boldsymbol{x})=0\)が分類結果の変化する境目となっている。つまり、\(\boldsymbol{x}\)の空間において\(f(\boldsymbol{x})=0\)となる\(\boldsymbol{x}\)は、二つのクラスを分ける境界を形成している。この境界を分類境界と呼ぶ。
このように決定関数を使って分類器を定義する方法は一般的であり、多くの分類手法が採用している。特に、式(1)を用いるものを線形サポートベクトル分類(Linear Support Vector Classification)と呼ぶ。
線形SVMでは、この\(\boldsymbol{w}\)と\(b\)をどのように推定するかが鍵となる。目的は、異なるクラスに属するデータ点をできるだけ正確に、かつマージン(クラス間の距離)を最大化するようにこれらのパラメータを決定することである。このプロセスを通じて、線形SVMは効果的な分類のための境界を提供する。
ハードマージン
まず、訓練集合内のすべての点を正しく分類できるようなベクトル\(\boldsymbol{w}\)とスカラー\(b\)の組が存在する場合を考える。この場合、訓練集合は関数\(f(\boldsymbol{x})\)によって分離可能であると表現する。ここで、あるラベル\(y_i\)に対して、もし分離に成功しているなら\(f(\boldsymbol{x}_i)\)の符号が\(y_i\)と一致する。つまり\(y_i f(\boldsymbol{x}_i) >0\)が成立する。これは、分離可能な訓練集合ではすべての\(i \in [n]\)に対して\(y_i f(\boldsymbol{x}_i) >0\)が成立することを意味する。
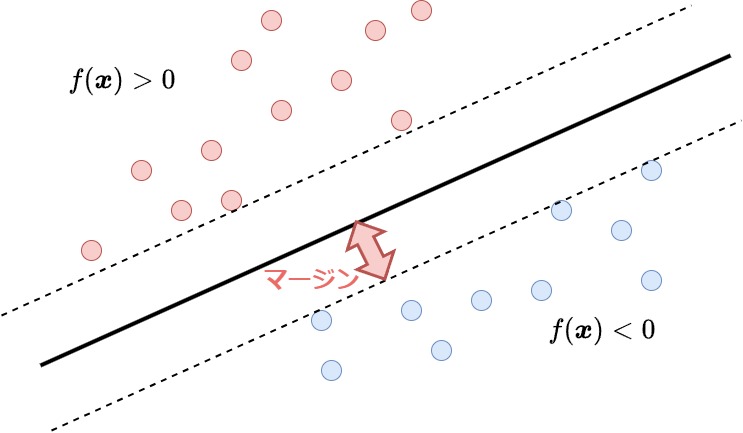
一般に、訓練集合を分離できる分類境界は複数存在しうる。サポートベクターマシンでは、それぞれのクラスのデータが分類境界からなるべく離れるようにして分類境界を定める。この分類境界と訓練データ間の最短距離をマージンと呼ぶ。
SVMの重要な特徴は、なるべくマージンが大きくなるような分類境界を求めることにある。これをマージン最大化と呼ぶ。マージンが大きいということは、分類境界がそれぞれのクラスのデータ点から離れているということであり、新しいデータ点が正しく分類される確率が高くなる。
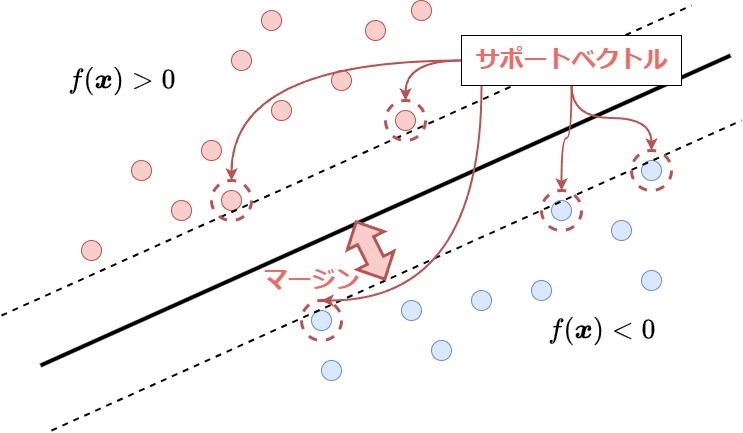
マージン最大化は分類境界と「分類境界から最も近くにある\(\boldsymbol{x}_i\)」との距離を最大化することで実現できる。この最も近くにある点\(\boldsymbol{x}_i\)をサポートベクトルと呼ぶ。
ある\(\boldsymbol{x}_i\)から分類境界までの距離は、点と平面の距離の公式から
$$
\frac{\left|\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right|}{\|\boldsymbol{w}\|}
$$
と表現できる。
すべての点を正しく分類するという条件は、\(y_i f(\boldsymbol{x}_i) >0\)であるべきである。正の実数\(M > 0\)を導入し、\(y_i f(\boldsymbol{x}_i) >M\)がすべての\(i \in [n]\)に成立しているとする。このとき、マージン最大化は以下の最適化問題によって表現できる。
$$
\begin{aligned} \max _{\boldsymbol{w}, b, M} & \frac{M}{\|\boldsymbol{w}\|} \\ \text { s.t. } & y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq M, i \in[n] \end{aligned}
$$
s.t.以降に続く条件式は制約条件と呼ばれ、上式は制約条件が満たされている範囲での最大値を求めるという意味である。
目的関数の値\(\frac{M}{\|\boldsymbol{w}\|} \)を最大化するためには\(M\)をなるべく大きくしたいが、\(M\)は制約条件\(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq M\)によってすべての\(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right)\)以下でなくてはならない。結果として\(M\)はすべての事例に対する\(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right)\)の値のうち最も小さい値と同じになる。そのような\(i\)を\(i'\)とすると
$$
\begin{aligned} \frac{M}{\|\boldsymbol{w}\|} & =\frac{y_{i^{\prime}}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i^{\prime}}+b\right)}{\|\boldsymbol{w}\|} \\ & =\frac{\left|\boldsymbol{w}^{\top} \boldsymbol{x}_{i^{\prime}}+b\right|}{\|\boldsymbol{w}\|} \end{aligned}
$$
となるため、目的関数の値は分類境界から最も近い点までの距離と一致することが分かる。 ここで、\(\boldsymbol{w}\)と\(b\)を\(M\)で割った\(\boldsymbol{w} / M\)と\(b/M\)を、それぞれ\(\tilde{\boldsymbol{w}}\) と \(\tilde{b}\)として置き換えると、より簡単な以下の形に帰着できる。
$$
\begin{aligned} \max _{\tilde{\boldsymbol{w}}, \tilde{b}} & \frac{1}{\|\tilde{\boldsymbol{w}}\|} \\ \text { s.t. } & y_i\left(\tilde{\boldsymbol{w}}^{\top} \boldsymbol{x}_i+\tilde{b}\right) \geq 1, i \in[n] \end{aligned}
$$
今後、この(\tilde{\boldsymbol{w}}\) と \(\tilde{b}\)を、\(\boldsymbol{w}\)と\(b\)として定義しなおして用いることとする。この\(\frac{1}{\| w \|}\)の最大化が、逆数である\(\|\boldsymbol{w}\|\)の最小化と等価なことと、\(\|\boldsymbol{w}\|\)の最小化はノルムを二乗した\(\|\boldsymbol{w}\|^2\)の最小化と等価であることを考慮すると、最適化問題はさらに扱いやすい以下の形に書き換えることができる。
$$
\begin{aligned} & \min _{\boldsymbol{w}, b}\|\boldsymbol{w}\|^2 \\ & \text { s.t. } y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq 1, i \in[n] \end{aligned}
$$
この最適化問題が分離可能性を仮定した場合の標準的な定式化で、このような分離可能性を仮定したうえでのSVMをハードマージンという。
ソフトマージン
ハードマージンでは訓練集合を完璧に分類する\(f(\boldsymbol{x})\)が存在するという仮定で成立するものだったが、実際の問題においてこの仮定は強すぎであり、クラスの分布が重なっているような場合もあり得る。このような場合にはハードバージンは汎化能力に優れるとは限らない。
SVMを分離可能でないデータに適用する場合には、ハードマージンを拡張したソフトマージンを考える。
この拡張は一部の訓練データの誤分類を許すように、制約条件である\(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b \geq 1\)を緩和することで導かれる。
具体的には、スラック変数と呼ばれる非負の変数\(\xi_i \geq 0, i \in[n]\)を導入し、制約条件\(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq 1\)を次のように緩和する。
$$
y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq 1-\xi_i, \quad i \in[n]
$$

丸く外側を囲まれた点はマージンを越えてしまった入力点\(\boldsymbol{x}_i\)を表す。ソフトマージンではこのような点の存在を許可することで、分離不可能な場合でも分類境界の推定を可能にする。
スラック変数\(\xi_n\)は各訓練データごとに定義される変数で、データが正しく分類され、かつマージン境界の上または外側に存在する場合は\(\xi_n =0\)、それ以外の場合には\(\xi_n = \mid t_n - y(\boldsymbol{x}_n) \mid\) として定義されるので、ちょうど分類境界\(y(\boldsymbol{x}) = 0\)上にあるデータについては\(\xi_n = 1\)、誤分類されたデータについては\(\xi_n > 1\)が成り立つ。
つまり、このスラック変数はデータ点がマージン内に侵入した場合のマージン境界からの距離に応じたペナルティと考えることができて、誤差関数を考える際にはこのペナルティがなるべく小さくなるようにすれば、マージン境界の「間違った側」の存在を許すようにハードマージンの定式化を修正したソフトマージンとなる。
改めてサポートベクターマシンの最適化問題の定義を次のように定義しなおすと次のようになる。
SVMの最適化主問題
$$
\begin{aligned}
\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} & \frac{1}{2}\|\boldsymbol{w}\|^2+C \sum_{i \in[n]} \xi_i \\
\text { s.t. } & y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq 1-\xi_i, i \in[n] \\
& \xi_i \geq 0, \quad i \in[n]
\end{aligned}
$$
ただし、添え字のない\(\boldsymbol{\xi}\)は\(\boldsymbol{\xi}=\left(\xi_1, \ldots, \xi_n\right)^{\top}\)を意味する。係数\(C\)は正則化係数と呼ばれる正の定数で事前に値を与えておかなければならないハイパーパラメータである。
この目的関数の第一項はハードマージンの場合と同様にマージン最大化の役割を持っていて、第二項はもともとの制約条件\(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b \geq 1\)に対する違反の度合いである\(\xi_i\)がなるべく小さくなるように抑制している項だと考えることができる。この項によってたとえマージンが大きくても誤分類が出すぎるような分類境界は作られにくくなる。
この第一項と第二項のバランスを調整するのが正則化係数\(C\)の役割であり、もしこれが\(C=\infty\)の場合、もし\(\xi_i \neq 0\)ならば無限大の値が目的関数に加えられてしまうので、\(\boldsymbol{\xi} = 0\)とならなければならない。これは\(C=\infty\)の場合はソフトマージンはハードマージンに一致するということを意味しており、ソフトマージンはハードマージンの一般化だと考えることができる。
双対表現
ここまでで定式化したマージン最大化の最適化問題はSVMの主問題と呼ばれる。しかし、この最適化を行うことは実際には難しいことが多い。
この主問題に対して双対問題という問題を導くことで、同じ最適化問題に対して違った見方を得ることができ、SVMの場合には主問題の代わりに双対問題を解くことでも主問題の解と同じ結果を得ることができるため、実用上では双対問題の方を計算している。
それは主問題と比べて、双対問題を解くことの方が以下のようなメリットがあるからである。
双対問題を考えることのメリット
- SVMにおいて双対問題が主問題よりも解きやすい場合が多い
- モデルをカーネルで表現することができるようになる
- 非線形化が可能になる
なので、次のSVMにおいて押さえておくべきカーネル法の前に双対表現について知っておかなければならない。
主問題
$$
\begin{aligned}
\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} & \frac{1}{2}\|\boldsymbol{w}\|^2+C \sum_{i \in[n]} \xi_i \\
\text { s.t. } & y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right) \geq 1-\xi_i, i \in[n] \\
& \xi_i \geq 0, \quad i \in[n]
\end{aligned}
$$
※この主問題はソフトマージンのものだが、先にも述べたように\(C= \infty\)とすればハードマージンとして解釈できるためこちらを使って考える。
では、この主問題から双対問題を導くためにまずは以下のように主問題を書き換える。
$$
\begin{aligned}
\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} & \frac{1}{2}\|\boldsymbol{w}\|^2+C \sum_{i \in[n]} \xi_i \\
\text { s.t. } & -\left(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right)-1+\xi_i\right) \leq 0, i \in[n] \\
& -\xi_i \leq 0, \quad i \in[n]
\end{aligned}
$$
ここでは新たに、\(\alpha_i \in \mathbb{R}^{+}, i \in[n]\)と\(\mu_i \in \mathbb{R}^{+}, i \in[n]\)という非負の変数を導入して、ラグランジュ関数を作ることができる。
$$
\begin{aligned}
L(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}, \boldsymbol{\mu})= & \frac{1}{2}\|\boldsymbol{w}\|^2+C \sum_{i \in[n]} \xi_i \\
& -\sum_{i \in[n]} \alpha_i\left(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right)-1+\xi_i\right)-\sum_{i \in[n]} \mu_i \xi_i
\end{aligned}
$$
ラグランジュの未定乗数法で用いられるラングランジュ関数である。ラグランジュの未定乗数法に関しての詳しい記事こちら、こっちも頑張って書いた渾身のやつなのでぜひぜひ読んで
-

ラグランジュの未定乗数法(KKT条件)の証明と直感的理解、そしてその幾何的解釈
この記事ではラグランジュの未定乗数法について徹底的に解説していく。 なぜラグランジュの未定乗数法はあれで導出することができるのか、厳密な証明、直感的な理解、幾何的な解釈をすべて取り扱う渾 ...
続きを見る

ここで、添え字のない\(\boldsymbol{\alpha},\boldsymbol{\mu}\)はベクトル\(\boldsymbol{\alpha}=\left(\alpha_1, \ldots, \alpha_n\right)^{\top},\boldsymbol{\mu}=\left(\mu_1, \ldots, \mu_n\right)^{\top}\)を意味する。さらに、\(\boldsymbol{w}, b, \boldsymbol{\xi}\)を主変数、\(\boldsymbol{\alpha},\boldsymbol{\mu}\)を双対変数と呼ぶ。
ラグランジュ関数から主問題への書き換え
ここでラグランジュ関数を双対変数について最大化した関数を\(\mathcal{P}(\boldsymbol{w}, b, \boldsymbol{\xi})\)として定義する。
$$
\mathcal{P}(\boldsymbol{w}, b, \boldsymbol{\xi})=\max _{\boldsymbol{\alpha} \geq 0, \boldsymbol{\mu} \geq 0} L(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}, \boldsymbol{\mu})
$$
この関数を主変数について最小化する以下の最適化問題を考える
ラグランジュ関数を使った主問題の書き換え
$$
\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} \mathcal{P}(\boldsymbol{w}, b, \boldsymbol{\xi})=\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} \max _{\alpha \geq 0, \boldsymbol{\mu} \geq 0} L(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}, \boldsymbol{\mu})
$$
これは、実は先ほどのSVMの主問題と同義である。
ラグランジュ関数から双対問題を定義する
先ほどは双対変数について最大化した関数\(\mathcal{P}(w, b, \boldsymbol{\xi})\)を定義したが、次は主変数について最小化した関数を定義する。
$$
\mathcal{D}(\boldsymbol{\alpha}, \boldsymbol{\mu})=\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} L(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}, \boldsymbol{\mu})
$$
そして、その後\(\mathcal{D}(\boldsymbol{\alpha}, \boldsymbol{\mu})\)を双対変数\(\boldsymbol{\alpha},\boldsymbol{\mu}\)について最大化する問題をSVMにおける双対問題として定義する。
SVMの双対問題
$$
\max _{\boldsymbol{\alpha} \geq \mathbf{0}, \boldsymbol{\mu} \geq \mathbf{0}} \mathcal{D}(\boldsymbol{\alpha}, \boldsymbol{\mu})=\max _{\boldsymbol{\alpha} \geq \mathbf{0}, \boldsymbol{\mu} \geq \mathbf{0}} \min _{\boldsymbol{w}, b, \boldsymbol{\xi}} L(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}, \boldsymbol{\mu})
$$
この双対問題は先ほどの「ラグランジュ関数を使った主問題の書き換え」の式の\(\min\)と\(\max\)を入れ替えた形になっている。
双対表現することのメリットの一つに、この最適化問題を双対変数のみで表記できることがある。どういうことかというと、この双対問題は次のように書き換えることができるのである。
SVMの双対問題
$$
\begin{aligned}
\max _\alpha & -\frac{1}{2} \sum_{i, j \in[n]} \alpha_i \alpha_j y_i y_j \boldsymbol{x}_i^{\top} \boldsymbol{x}_j+\sum_{i \in[n]} \alpha_i \\
\text { s.t. } & \sum_{i \in[n]} \alpha_i y_i=0 \\
& 0 \leq \alpha_i \leq C, i \in[n]
\end{aligned}
$$
※一般的にSVMの双対問題とはこちらを指すことが多い。
主問題と双対問題の関係
ここまでの議論をまとめると、マージン最大化から主問題を導き、それがラグランジュ関数を用いた形で書けることを示したのち、さらにラグランジュ関数から双対問題というものを定義したところである。
もともと、求めたかったのはマージンを最大化してくれるような分類境界を作る線形関数\(f(\boldsymbol{x})=\boldsymbol{w}^{\top} \boldsymbol{x}+b\)であり、それはこの主問題を解くことによって求められるはずだった。
しかし、先ほどの双対問題の書き換えの議論より、双対問題では変数が結局\(\boldsymbol{\alpha}\)のみになるし、のちのち様々なメリットがあるので、できれば双対問題で解きたいところ
しかし、主問題と双対問題の関係が今不鮮明である。
なのでここからは主問題と双対問題の間にどのような関係があるのかを考えていく。

弱双対性
主問題の最適解を\(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*\)、双対問題の最適解\(\boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\)が存在すると仮定する。この時以下の関係が成立する。
$$
\begin{aligned}
\mathcal{D}\left(\boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right) & =\min _{\boldsymbol{w}, b, \boldsymbol{\xi}} L\left(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right) \\
& \leq L\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*, \boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right)\\
& \leq \max _{\alpha \geq 0, \mu \geq 0} L\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*, \boldsymbol{\alpha}, \boldsymbol{\mu}\right)=\mathcal{P}\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*\right)
\end{aligned}
$$
よって双対問題の最適値が主問題の最適値以下であるという関係が分かった。
$$
\mathcal{D}\left(\boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right) \leq \mathcal{P}\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*\right)
$$
これは弱双対性と呼ばれる性質であり、一般に成立する。
よって、まず次のようになる。

強双対性
さらに、実はサポートベクターマシンの場合、より強い強双対性という性質が成り立つ。
強双対性とは以下が成り立つことである。
$$
\mathcal{D}\left(\boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right)=\mathcal{P}\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*\right)
$$
この性質が意味するところは、主問題と双対問題の目的関数値が最適解において一致するということである。
証明はこちらの記事で行っている
-
サポートベクターマシン(SVM)の最適化
この記事ではサポートベクターマシン(SVM)の最適化問題について特化して詳しく解説していく。 SVMのマージン最大化などの基本的な理論についてはこちらの記事を参考にしてほしい。むしろ順番としてはこちら ...
続きを見る


鞍点定理
強双対性が成立するときとはどういう状況なのか、幾何的な側面から考えてみると以下の鞍点定理というのが成り立つことが知られている。
鞍点定理
$$
L\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*, \boldsymbol{\alpha}, \boldsymbol{\mu}\right) \leq L\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*, \boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right) \leq L\left(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right)
$$
この不等式は、\(L\left(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*, \boldsymbol{\alpha}^*, \boldsymbol{\mu}^*\right)\)が主変数\(\boldsymbol{w}^*, b^*, \boldsymbol{\xi}^*\)については極小値であり、双対変数\(\boldsymbol{\alpha},\boldsymbol{\mu}\)については極大値であることを意味する。このような点は関数の鞍点と呼ばれる。
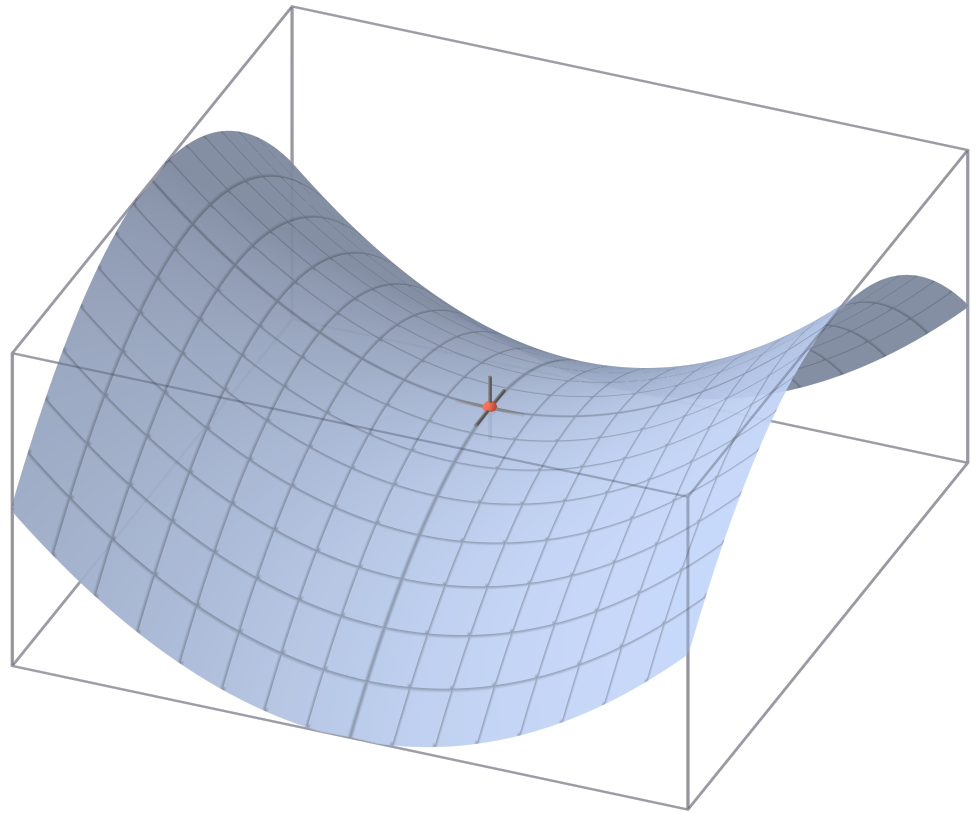
主問題と双対問題が最適解であるラグランジュ関数の鞍点に対して異なる方向からアプローチするものだということが分かる。
最適性条件
というわけで、主問題ではなく双対問題を最適化すればよいというところまで来た。
最適化問題の解を得るには、解の最適性を判定するための条件を知る必要がある。
KKT条件
以下の条件がSVMの主変数、双対変数の最適性の必要十分条件である。
$$
\begin{align*}
\frac{\partial L}{\partial w}=\boldsymbol{w}-\sum_{i \in[n]} \alpha_i y_i \boldsymbol{x}_i & =\mathbf{0} \tag{1}\\
\frac{\partial L}{\partial b}=-\sum_{i \in[n]} \alpha_i y_i & =0 \tag{2}\\
\frac{\partial L}{\partial \xi_i}=C-\alpha_i-\mu_i & =0, i \in[n] \tag{3}\\
-\left(y_i\left(\boldsymbol{w}^{\top} \phi\left(\boldsymbol{x}_i\right)+b\right)-1+\xi_i\right) & \leq 0, i \in[n] \tag{4}\\
-\xi_i & \leq 0, i \in[n] \tag{5}\\
\alpha_i & \geq 0, i \in[n] \tag{6}\\
\mu_i & \geq 0, i \in[n] \tag{7}\\
\alpha_i\left(y_i\left(\boldsymbol{w}^{\top} \phi\left(x_i\right)+b\right)-1+\xi_i\right) & =0, i \in[n] \tag{8}\\
\mu_i \xi_i & =0, i \in[n] \tag{9}
\end{align*}
$$
(1)~(3)はラグランジュ関数の主変数に関する微分であり、次の(4),(5)は主問題の制約条件,(6),(7)は双対変数の非負条件であり、最後の二つ(8),(9)は双対変数と不等制約の乗算によって定義される相補性条件と呼ばれる条件である。
KKT条件がSVMの最適化における必要十分条件であることの証明は同じく以下の記事で行っている。
-
サポートベクターマシン(SVM)の最適化
この記事ではサポートベクターマシン(SVM)の最適化問題について特化して詳しく解説していく。 SVMのマージン最大化などの基本的な理論についてはこちらの記事を参考にしてほしい。むしろ順番としてはこちら ...
続きを見る
SVMにおけるKKT条件の使い方

双対問題を解いて\(\boldsymbol{\alpha}\)のみが求まったとすると、このとき式(1)から得られる\(\boldsymbol{w}=\sum_{i \in[n]} \alpha_i y_i \boldsymbol{x}_i\)という関係が得られ
さらに、相補性条件である(8)より、\(\alpha_i > 0\)のとき、\(y_i\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i+b\right)-1-\xi_i=0\)が成り立ち、(3)から得られる\(\mu_i=C-\alpha_i\)を(9)に代入すると、\(\left(C-\alpha_i\right) \xi_i=0\)となり、\(\alpha_i < C\)であれば\(\xi_i = 0\)でなければならないことがわかり結果として
$$
y_i\left(\boldsymbol{w}^{\top} x_i+b\right)-1=0, i \in\left\{i \in[n] \mid 0<\alpha_i<C\right\}
$$
となり、ここから先の\(\boldsymbol{w}=\sum_{i \in[n]} \alpha_i y_i \boldsymbol{x}_i\)と併せると
$$
b=y_i-\sum_{i^{\prime} \in[n]} \alpha_{i^{\prime}} y_{i^{\prime}} x_{i^{\prime}}^{\top} x_i, i \in\left\{i \in[n] \mid 0<\alpha_i<C\right\}
$$
得られたすべてを合わせれば\(\boldsymbol{\alpha}\)を得ることさえできれば、当初から求めたかった決定関数が得られるのである。
\(f(x)=\sum_{i \in[n]} \alpha_i y_i x_i^{\top} x+y_i-\sum_{i^{\prime} \in[n]} \alpha_{i^{\prime}} y_{i^{\prime}} x_{i^{\prime}}^{\top} x_i, i \in\left\{i \in[n] \mid 0<\alpha_i<C\right\}\)
ではどのように双対問題から\(\boldsymbol{\alpha}\)を求めるのかというと、サポートベクターマシン(SVM)の訓練を効率的に行うために開発された方法であるSMOアルゴリズムなどを用いて行われる。
カーネル法による一般化
さてここまで来たらようやくSVMで押さえておくべき項目の二つ目のカーネル法を紹介する。
これまでは線形に分離することを考えてきたが、世の中のデータには線形で分離できないものも存在する。
双対問題はSVMの非線形化を考える上で重要な役割を果たす。入力\(\boldsymbol{x}\)を何らかの特徴空間\(\mathcal{F}\)へ写像する関数\(\phi: \mathbb{R}^d \rightarrow \mathcal{F}\)を考える。この\(\phi(\boldsymbol{x})\)を新たな特徴ベクトルだと考えると決定関数は
\(f(\boldsymbol{x})=\boldsymbol{w}^{\top} \boldsymbol{\phi}(\boldsymbol{x})+b\)

写像\(\phi\)が非線形ならば、入力空間(左)では決定関数\(f(\boldsymbol{x})=\boldsymbol{w}^{\top} \boldsymbol{\phi}(\boldsymbol{x})+b\)は非線形の分類境界を形成する。一方\(\phi(\boldsymbol{x}\)は\(\phi(boldsymbol{x})\)に関しては1次なので右は線形に分離できる。
なので、特徴空間に写した後の\(\phi(\boldsymbol{x})\)を新たな特徴ベクトルとみなして\(\boldsymbol{x}\)と置き換えればこれまでの計算はすべて成立する。
双対問題はこのように書き換えることができる
一般化された双対問題
$$
\begin{aligned}
\max _{\boldsymbol{\alpha}} & -\frac{1}{2} \sum_{i, j \in[n]} \alpha_i \alpha_j y_i y_j \phi\left(x_i\right)^{\top} \phi\left(x_j\right)+\sum_{i \in[n]} \alpha_i \\
\text { s.t. } & \sum_{i \in[n]} \alpha_i y_i=0 \\
& 0 \leq \alpha_i \leq C, i \in[n]
\end{aligned}
$$
この双対問題において\(\phi\)は内積\(\phi\left(x_i\right)^{\top} \phi\left(x_j\right)\)という形でのみ現れている、これはこの最適化問題を解く上で直接その内積を計算する必要はなく、カーネル関数を用いたカーネルトリックと呼ばれる方法を用いることで\(\phi(\boldsymbol{x})\)を計算することなく行うことができる。
カーネル関数は以下のように定義する。
$$
K\left(x_i, x_j\right)=\phi\left(x_i\right)^{\top} \phi\left(x_j\right)
$$
カーネル関数を使うと双対問題は次のように書ける
カーネル法を用いて一般化された双対問題
$$
\begin{array}{ll}
\max _\alpha & -\frac{1}{2} \sum_{i, j \in[n]} \alpha_i \alpha_j y_i y_j K\left(\boldsymbol{x}_i, \boldsymbol{x}_j\right)+\sum_{i \in[n]} \alpha_i \\
\text { s.t. } & \sum_{i \in[n]} \alpha_i y_i=0 \\
& 0 \leq \alpha_i \leq C, i \in[n]
\end{array}
$$
そして\(f(\boldsymbol{x})\)もカーネル関数によって次のように表現できる
$$
f(x)=\sum_{i \in[n]} \alpha_i y_i K\left(\boldsymbol{x}_i, \boldsymbol{x}\right)+b
$$
SVMのまとめ
2クラス分類でのSVMをできうる限り厳密に解説した、まとめると
SVMはできうる限り大きいマージンでデータを分類できるような境界を表す関数\(f(\boldsymbol{x})\)を探すものである。
それは双対表現という考え方を通してKKT条件に基づき最適化され、たとえ線形(直線)で分離できなくてもカーネル法を用いることで非線形においても適用できる。
冒頭でも述べたように、SVMは現在でもまだまだ現役で威力を発揮するAIモデルである。
メリットは様々だが、この最適化問題は凸二次最適化問題とよばれ、これの良いところはどのような初期値から最適化を始めても大域的最適解にたどり着くということである。これは非常に優れた利点の一つである。
参考先


