
この記事では、様々な機械学習アルゴリズムを構築するためのパーツとなる各種基本的な確率分布の定義と、その用途や性質を解説する。
非常にヘビーな記事で文字数にして三万文字近くある。
めちゃめちゃ丁寧に解説した魂の記事なのでぜひ読んでほしい。
確率分布は機械学習を学ぶ上で避けては通れないところで、この記事はその確率分布の理解の助けとなるべく書いたものである。
ただ、僕も勉強中の身なので、何か間違いなどがあればコメント等で教えてほしい。
離散確率分布の関係性

今回の流れはまずはもっとも簡単なベルヌーイ分布という分布の定義や性質をみて尤度関数まで考えていく。
そしてそのベルヌーイ分布を複数回の試行に拡張した二項分布というのを見て、
ここでベイズ的なアプローチとして事前分布を導入するためにベータ分布というものを考える。
これは機械学習においてとても重要な連続な確率分布であり、丁寧に扱っていく。
そしてここまでの流れを多次元に拡張し、改めて考えていくべくベルヌーイ分布を多次元に拡張したカテゴリ分布というものを確認し
同じく複数回の試行に拡張させた多項分布というものを考えたのち、多項分布に対し導入できる事前分布であるディリクレ分布という計六つの確立分布を紹介していく。
とまぁ、このようにこの記事ではたくさんの「分布」が出てくる。今、なんの分布の話をしていて、それはほかの分布に対してどのような関係でどのような役割を担っているのかを常に意識しながらこれから出てくる分布をみてほしい。
迷子になったら適宜上の図を見てほしい。
ベルヌーイ分布

ベルヌーイ分布とは、二値変数(0 または 1 のどちらかの値を取る変数)に関する離散確率分布のことである。例えば、コイン投げにおいて表が出る確率を\(\mu\)とし、裏が出る確率を\(1-\mu\)とすると、ベルヌーイ分布はこのような確率分布を表現する。
二値変数 \(x\) がベルヌーイ分布に従うとき、その確率質量関数(確率変数が特定の値を取る確率を表す関数)は以下のように定義される。
【定義】ベルヌーイ分布
$$ {Bern}(x \mid \mu) = \mu^x (1 - \mu)^{1 - x} $$
まず、二値変数 \(x\) が \(1\) の場合と \(0\) の場合をそれぞれ考える。
- \(x = 1\) の場合:
このとき、確率質量関数は表が出る確率 \(\mu\) である。すなわち、\(p(x=1 \mid \mu) = \mu\) となる。
- \(x = 0\) の場合:
このとき、確率質量関数は裏が出る確率 \(1 - \mu\) である。すなわち、\(p(x=0 \mid \mu) = 1 - \mu\) となる。
次に、ベルヌーイ分布が正規化されていることを確認する。正規化とは、全ての確率の和が 1 になることである。二値変数 \(x\) は 0 か 1 のどちらかの値を取るため、以下のように確率の和を計算する。
$$ \sum_{x=0}^1 {Bern}(x \mid \mu) = {Bern}(0 \mid \mu) + {Bern}(1 \mid \mu) $$
$$ = \mu^0 (1 - \mu)^{1 - 0} + \mu^1 (1 - \mu)^{1 - 1} $$
$$ = (1 - \mu) + \mu = 1 $$
確率の和が 1 になることが確認できたため、ベルヌーイ分布は正規化されている。
ベルヌーイ分布の期待値と分散
ベルヌーイ分布の期待値 \(\mathbb{E}[x]\) と分散 \({var}[x]\) は次のようになる
ベルヌーイ分布の期待値と分散
$$\mathbb{E}[x] = \mu$$
$${var}[x] = \mu(1 - \mu)$$
頻度主義的にベルヌーイ分布の尤度関数を考える
-

【確率論】頻度主義とベイズ主義、尤度関数の最大化したい理由を解説【機械学習】
さていよいよベイズ確率に入っていく。 今回の記事ではこれまで見てきた一般的な確率とベイズ確率がどのように違うのか、そして尤度関数の最大化という視点がなぜ必要なのかを見ていく。 ベイズ確率は機械学習を学 ...
続きを見る

尤度関数は、与えられたデータセット \(\mathcal{D}={x_1, \ldots, x_N}\) が得られる確率を表す。これはベルヌーイ分布の確率質量関数を用いて次のように計算できる。
$$ p(\mathcal{D} \mid \mu) = \prod_{n=1}^N p(x_n \mid \mu) $$
ここで、ベルヌーイ分布の確率質量関数 \(p(x_n \mid \mu) = \mu^{x_n}(1 - \mu)^{1 - x_n}\) を代入する。これがベルヌーイ分布の確立
$$ p(\mathcal{D} \mid \mu) = \prod_{n=1}^N \mu^{x_n}(1 - \mu)^{1 - x_n} $$
尤度関数の最大化は、対数をとることで簡単になる。対数は単調増加関数であるため、尤度関数の最大化と対数尤度の最大化が等価である。
対数尤度を計算する。
$$ \ln p(\mathcal{D} \mid \mu) = \sum_{n=1}^N \ln p(x_n \mid \mu) $$
$$ \ln p(\mathcal{D} \mid \mu) = \sum_{n=1}^N \ln ( \mu^{x_n}(1 - \mu)^{1 - x_n} ) $$
$$ = \sum_{n=1}^N ( x_n \ln \mu + (1 - x_n) \ln (1 - \mu) ) $$
十分統計量について
十分統計量とは、パラメータを推定するために必要な情報をデータから集約した統計量である。十分統計量が分布のパラメータに対して「十分」な情報を持っていれば、データセット全体を用いるよりも効率的にパラメータを推定できる。
対数尤度の和の中で、\(\sum_{n=1}^N x_n\) と \(\sum_{n=1}^N (1 - x_n)\) がそれぞれ現れている。これらの和がベルヌーイ分布の下でのデータに対する十分統計量である理由を説明する。
先ほど導出した対数尤度は以下の通りであった。
$$ \ln p(\mathcal{D} \mid \mu) = \sum_{n=1}^N ( x_n \ln \mu + (1 - x_n) \ln (1 - \mu) ) $$
ここで、\(\sum_{n=1}^N x_n\) は、データセット \(\mathcal{D}\) で \(x_n = 1\) となるデータの数を表す。同様に、\(\sum_{n=1}^N (1 - x_n)\) は、データセット \(\mathcal{D}\) で \(x_n = 0\) となるデータの数を表す。これらの値は、データセットに関する情報を要約したものであり、パラメータ \(\mu\) の推定に必要な情報を持っている。
十分統計量の性質を持つためには、以下の条件を満たす必要がある。
- その統計量がパラメータに関する情報を持っていること。
- 他のデータに関する余分な情報を持っていないこと。
対数尤度の和において、\(\sum_{n=1}^N x_n\) と \(\sum_{n=1}^N (1 - x_n)\) は、これらの条件を満たす。つまり、これらはベルヌーイ分布のパラメータ \(\mu\) に関する情報を持っており、他のデータに関する余分な情報は持っていない。
このため、\(\sum_{n=1}^N x_n\) と \(\sum_{n=1}^N (1 - x_n)\) は、ベルヌーイ分布の下でのデータに対する十分統計量と言える。これらの統計量を利用すれば、効率的にパラメータ \(\mu\) を推定できる。
最尤推定量(サンプル平均)
最尤推定量は先の対数尤度関数から次のように求めることができる
最尤推定量(サンプル平均)
$$ \mu_{\mathrm{ML}} = \frac{1}{N} \sum_{n=1}^N x_n $$
最尤推定量 \(\mu_{\mathrm{ML}}\) はサンプル平均とも呼ばれる
最尤推定の弱点
次に、コインを 3 回投げ、すべて表が出た場合の最尤推定の弱点について説明する。この場合、データセットは \(\mathcal{D} = {1, 1, 1}\) である。最尤推定量を計算すると、
$$ \mu_{\mathrm{ML}} = \frac{1}{3} \sum_{n=1}^3 x_n $$
$$= \frac{1}{3}(1 + 1 + 1) = 1 $$
となる。すなわち、最尤推定によると、コインの表が出る確率 \(\mu_{\mathrm{ML}}\) は 1 と推定される。しかし、これはコインが必ず表になるという極端な結果であるため、実際の確率に対してバイアスがかかっていると考えられる。
このように、データ数が少ない場合、特にすべてのデータが同じ値を持つ場合には、最尤推定が極端な推定値を与えることがある。これは最尤推定の弱点であり、データ数が少ない場合や特定の結果が偶然多く観測された場合に、過剰な信頼性が生じる可能性がある。この問題を緩和するために、ベイズ推定などの手法が用いられることがある。
対数尤度関数が一意であることの証明はこちら
-
確率論を使った多項式曲線フィッティングの流れを段階的に徹底解説する【ベイズ】
本記事では、データ解析の基本となる曲線フィッティングを、確率論を用いて理解するための解説を行っている。 最尤推定やベイズの定理を駆使し、パラメータ推定から予測分布の計算までを、そもそもなぜ最尤推定をし ...
続きを見る

二項分布

ベルヌーイ分布が表すのは、1 回の試行での 2 つの結果の出る確率である。それに対し、二項分布は複数回の試行である特定の結果が出る回数の確率を表す。
ここでは、試行回数を \(N\)、そのうち \(x=1\) となる観測値の数を \(m\) とし、各試行で \(x=1\) が出る確率を \(\mu\) とする。各試行は独立であると仮定し、ベルヌーイ分布に従う。
一般に、\(N\) 回の試行で特定の結果が \(m\) 回出る組み合わせの数は、\(N\) を \(m\) で割る組み合わせの数であり、次のように表される。
$$
\left(\begin{array}{l}
N \\
m
\end{array}\right) \equiv \frac{N !}{(N-m) ! m !}
$$
これは、「\(N\) 人の中から \(m\) 人を選ぶ組み合わせの数」を表す。数学的には、\(N!\) は \(N\) の階乗、つまり \(N\) から 1 までの全ての自然数の積を表し、\(m!\) は \(m\) の階乗、つまり \(m\) から 1 までの全ての自然数の積を表す。
次に、各試行で \(x=1\) が出る確率は \(\mu\) であり、これが \(m\) 回出る確率は \(\mu^m\) となる。また、試行で \(x=0\) が出る確率は \(1-\mu\) であり、これが \(N-m\) 回出る確率は \((1-\mu)^{N-m}\) となる。
以上を組み合わせると、\(N\) 回の試行で \(x=1\) が \(m\) 回出る確率は、以下のように表され、これが二項分布である。
【定義】二項分布
$$
{Bin}(m \mid N, \mu)=\left(\begin{array}{l}
N \\
m
\end{array}\right) \mu^m(1-\mu)^{N-m}
$$
つまり、二項分布は、「\(N\) 回の試行で特定の結果が \(m\) 回出る確率」を表す分布である。
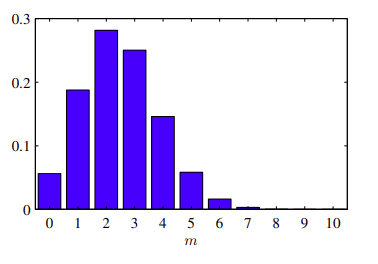
N=10, μ=0.25のときの二項分布をmの関数として示したヒストグラム
二項分布の平均と分散
二項分布の平均と分散は以下のようになる
二項分布の平均と分散
$$ \begin{aligned} \mathbb{E}[m] \equiv \sum_{m=0}^N m \operatorname{Bin}(m \mid N, \mu) & =N \mu \\ \operatorname{var}[m] \equiv \sum_{m=0}^N(m-\mathbb{E}[m])^2 \operatorname{Bin}(m \mid N, \mu) & =N \mu(1-\mu) \end{aligned} $$
期待値と分散の線形加法性
2変数 \(x, z\) が統計的に独立であるとする。それらの和の平均と分散が
$$
\begin{gathered}
\mathbb{E}[x+z]=\mathbb{E}[x]+\mathbb{E}[z] \\
\operatorname{var}[x+z]=\operatorname{var}[x]+\operatorname{var}[z]
\end{gathered}
$$
を満たす
ベータ分布

先ほどのサンプル平均のところの話で、頻度主義的なアプローチではデータ集合が小さいと過学習がおこりやすいということがあった。なのでベイズ的なアプローチを見ていこう。
まず、パラメータ \(\mu\) の事前分布 \(p(\mu)\) について考える。ベイズ主義では、事前分布というものを設定してパラメータの不確かさを表現する。これは、パラメータが取り得る値の事前の信念を表している。
ここで事前分布として \(\operatorname{Beta}(\mu \mid a, b)\) 分布を考える。この分布は下記のように定義される:
【定義】ベータ分布
$$ \operatorname{Beta}(\mu \mid a, b)=\frac{\Gamma(a+b)}{\Gamma(a) \Gamma(b)} \mu^{a-1}(1-\mu)^{b-1} $$
ここで、\(\Gamma(x)\) はガンマ関数で、次のように定義される:
$$ \Gamma(x) = \int_0^{\infty} u^{x-1} e^{-u} \mathrm{~d} u $$
ガンマ関数は一般化された階乗とも言える関数で、整数以外の値に対しても定義されている。
ベータ分布は \([0, 1]\) の範囲の値を取る連続確率変数の分布で、パラメータ \(\mu\) が取り得る値の範囲と一致する。
ベータ分布の係数について
定義の中にある係数
$$\frac{\Gamma(a+b)}{\Gamma(a) \Gamma(b)}$$は、ベータ分布が正規化されることを保証するためのもの
$$
\begin{aligned}
\Gamma(a) \Gamma(b) & =\int_0^{\infty} \exp (-x) x^{a-1} \mathrm{~d} x \int_0^{\infty} \exp (-y) y^{b-1} \mathrm{~d} y \\
& =\int_0^{\infty} \int_0^{\infty} \exp (-x) x^{a-1} \exp (-y) y^{b-1} \mathrm{~d} y \mathrm{~d} x \\
& =\int_0^{\infty} \int_x^{\infty} \exp (-x) x^{a-1} \exp (x-t)(t-x)^{b-1} \mathrm{~d} t \mathrm{~d} x \\
& =\int_0^{\infty} \int_x^{\infty} \exp (-t) x^{a-1}(t-x)^{b-1} \mathrm{~d} t \mathrm{~d} x \\
& =\int_0^{\infty} \int_0^t \exp (-t) x^{a-1}(t-x)^{b-1} \mathrm{~d} x \mathrm{~d} t \\
& =\int_0^{\infty} \int_0^1 \exp (-t)(t \mu)^{a-1}(t-t \mu)^{b-1} t \mathrm{~d} \mu \mathrm{d} t \\
& =\int_0^{\infty} \exp (-t) t^{a+b-1} \int_0^1 \mu^{a-1}(1-\mu)^{b-1} \mathrm{~d} \mu \mathrm{d} t \\
& =\int_0^{\infty} \exp (-t) t^{a+b-1} \mathrm{~d} t \int_0^1 \mu^{a-1}(1-\mu)^{b-1} \mathrm{~d} \mu \\
& =\Gamma(a+b) \int_0^1 \mu^{a-1}(1-\mu)^{b-1} \mathrm{~d} \mu
\end{aligned}
$$
ここで四行目から五行目の変形で積分順序を t, x の順番から x, t の順番へと入れ替えているが、積分区間は図 1 の
水色の領域で、積分順序を入れ替えることにより、積分区間が図 2 のように変わることに注意。

したがって$$
\int_0^1 \mu^{a-1}(1-\mu)^{b-1} \mathrm{~d} \mu=\frac{\Gamma(a) \Gamma(b)}{\Gamma(a+b)}
$$
ベータ分布の特徴
パラメータaとbは、パラメータμの分布を決めるので超パラメータと呼ばれる。
(青の実線は平均値・破線は最頻値を示している)

ベータ分布の形状
- \(a=b=1\)の場合
標準一様分布になる
平均値=最頻値になる - \(a=b>1\)の場合
正規分布の形になる
平均値=最頻値になる - \(a<1 ,or, b<1\)の場合
\(\mu=0,\mu=1\)のどちらかもしくは両方で特異性を持つ(発散する) - \(a>b\)の場合
左肩下がりのグラフになる
最頻値が平均値より右側になる - \(a<b\)の場合
右肩下がりのグラフになる
平均値が最頻値より右側になる
このようにパラメータa,bの値によって、グラフの形状が大きく変わる。形状がとても柔軟なので、事前確率分布として非常に扱いやすい。
これがベイズ統計においてベータ分布が特に重要な役割を担う大きな理由のひとつである。
ベータ分布の平均と分散と最頻値
ベータ分布の平均と分散と最頻値(モード)は
$$
\begin{aligned}
\mathbb{E}[\mu] & =\frac{a}{a+b} \\
\operatorname{var}[\mu] & =\frac{a b}{(a+b)^2(a+b+1)}\\
\operatorname{mode}[\mu]&=\frac{a-1}{a+b-2}
\end{aligned}
$$
と与えられる
次にベータ分布を事前分布とした時の事後分布を考える。ベイズの定理によれば、事後分布は尤度関数と事前分布の積に比例する。つまり、
$$ p(\mu \mid \mathcal{D}) \propto p(\mathcal{D} \mid \mu) p(\mu) $$
ここで、尤度関数 \(p(\mathcal{D} \mid \mu)\) はベルヌーイ分布の積で、\(\mu^x(1-\mu)^{1-x}\) の形をしている。
したがって、事後分布は以下のようになる:
$$ p(\mu \mid \mathcal{D}) \propto \mu^x(1-\mu)^{1-x} \cdot \operatorname{Beta}(\mu \mid a, b) $$
これは、ベータ分布と同じ形の積になっていることがわかる。これを共役性と言い、ベータ分布を事前共役分布として選ぶ理由である。
実際に右辺はベータ分布として簡潔に表すことができてベータ分布の定義と比較して
【復習】ベータ分布の定義
$$ \operatorname{Beta}(\mu \mid a, b)=\frac{\Gamma(a+b)}{\Gamma(a) \Gamma(b)} \mu^{a-1}(1-\mu)^{b-1} $$
ベータ分布の事後分布
$$
p(\mu \mid m, l, a, b)=\frac{\Gamma(m+a+l+b)}{\Gamma(m+a) \Gamma(l+b)} \mu^{m+a-1}(1-\mu)^{l+b-1} .
$$
これを踏まえて、データ集合に \(x=1\) となる観測値が \(m\) 個、\(x=0\) となる観測値が \(l\) 個ある場合を考える。このデータ集合を観測した後の事後分布は、事前分布のパラメータ \(a\) を \(m\) だけ、\(b\) を \(l\) だけ増やすことで得られる。つまり、
$$ \operatorname{Beta}(\mu \mid a+m, b+l) $$
となる。このことから、超パラメータ \(a\) と \(b\) はそれぞれ、\(x=1\) の観測数と \(x=0\) の観測数に対応する「有効観測数」として解釈できる。つまり、ベータ分布のパラメータ \(a, b\) は、それぞれ \(x=1\) と \(x=0\) の出現傾向を表しており、それぞれの観測数を加算することで、データの情報を反映した事後分布を得ることができるのである。
逐次推論

ある観測データ\(x\)が与えられたとき、パラメータ\(\mu\)の事後分布を求めたいとする。これはベイズの定理を用いて計算できる。ベイズの定理は以下のように表される。
$$ p(\mu|x) = \frac{p(x|\mu) p(\mu)}{p(x)} $$
ここで、\(p(x|\mu)\)は尤度、\(p(\mu)\)は事前分布、\(p(\mu|x)\)は事後分布をそれぞれ表す。
この式から、事後分布は尤度と事前分布の積に比例することがわかる。すなわち、新たなデータ\(x\)を観測するたびに、パラメータ\(\mu\)の事後分布を計算し直すことで、パラメータの推定値を更新することができる。これが逐次的なベイズ推論の基本的な考え方である。
具体的には、初めに\(\mu\)の事前分布を設定し、新たなデータ\(x\)を観測するたびに、尤度\(p(x|\mu)\)と事前分布\(p(\mu)\)を掛け合わせて事後分布\(p(\mu|x)\)を計算する。そして、この事後分布を新たな事前分布として用い
この新たな事前分布を元に、再度新たなデータが観測されたときの尤度と掛け合わせて、事後分布を更新する。これをデータがなくなるまで繰り返す。これが逐次推論の全体の流れだ。
このように、新たな観測データが得られるたびにパラメータの確信度を更新することで、データに基づくモデルの予測能力を高めることができる。機械学習の用語では、このような手法を逐次学習(sequential learning)や追加学習(incremental learning),オンライン学習(online learning)などと呼ばれたりし、アプリケーションのリアルタイム性を求められる場合やデータ集合全体をメモリ全体に展開しなくてよいことからメモリ効率を重視したい場合によく使われる。
ベイズ学習の特性
事後平均の位置について
次に以下の予測分布を考えてみる。
$$ p(x=1 \mid \mathcal{D})=\int_0^1 p(x=1 \mid \mu) p(\mu \mid \mathcal{D}) \mathrm{d} \mu=\int_0^1 \mu p(\mu \mid \mathcal{D}) \mathrm{d} \mu=\mathbb{E}[\mu \mid \mathcal{D}] $$
この式は、観測データ集合 \(\mathcal{D}\) が与えられたときの \(x=1\) の予測分布を表している。すなわち、これから新たに試行を行ったときに \(x=1\) となる確率を求めている。
右辺の積分は、全ての \(\mu\) の値に対して、\(x=1\) となる確率 \(p(x=1 \mid \mu)\) と、その \(\mu\) の値が観測データ集合 \(\mathcal{D}\) から得られる確率 \(p(\mu \mid \mathcal{D})\) の積を取っている。つまり、全ての \(\mu\) の値に対して、その値が観測データ集合から得られる確率を重みとして、\(x=1\) となる確率を平均化している。そして、この値は \(\mu\) の事後分布の期待値 \(\mathbb{E}[\mu \mid \mathcal{D}]\) となる。
事後分布はこうなるのであった
$$ p(\mu \mid m, l, a, b)=\frac{\Gamma(m+a+l+b)}{\Gamma(m+a) \Gamma(l+b)} \mu^{m+a-1}(1-\mu)^{l+b-1} $$
ベータ分布の平均は以下のように表される。
$$ \mathbb{E}[\mu]=\frac{a}{a+b} $$
これは、ベータ分布に従う確率変数 \(\mu\) の期待値、すなわち平均値を表している。この値を利用すると、
$$ p(x=1 \mid \mathcal{D})=\frac{m+a}{m+a+l+b} $$ となる。これが求めていた予測分布である。
この式はどう理解すればいいのだろうか。\(m+a\) とは、実際の観測値 \(m\) と仮想的な事前の観測値(超パラメータ)\(a\) の和を表しており、これは「\(x=1\) に相当する観測値」を意味する。同様に、\(m+a+l+b\) は全観測値(\(x=1\) と \(x=0\) の両方)の合計を表す。従って、この分母は「全ての観測値」を意味する。
よって、\(p(x=1 \mid \mathcal{D})=\frac{m+a}{m+a+l+b}\) は、「全ての観測値の中で \(x=1\) に相当する観測値が占める割合」、すなわち「次の試行で \(x=1\) となる予測確率」を意味する。
ベイズの公式から,事後分布は事前分布と尤度関数の積になっている,事後分布というのは事前分布と尤度関数の両方を踏まえたうえでの分布になっているので、あるパラメータに関して,事後分布の期待値を取ると,事前分布の期待値と最尤推定量との間になることは直感的にはそうである。
実際、事後分布の期待値、すなわち\(\mu\)の事後平均が、事前平均と最尤推定量の間に位置する
そして\( m, l \rightarrow \infty \)とすると、\(\mu\)の最尤推定は
$$\mu_{\mu L}=\frac{m}{m+l} $$
だったことから、$$ p(x=1 \mid \mathcal{D})=\frac{m+a}{m+a+l+b} $$ は最尤推定の結果に近づく。つまり無限に大きなデータ集合での極限では、ベイズと最尤推定の結果は一致するということなのである。
データ量の増加→不確実性の減少
さらに分散では、これまで見てきたベータ分布はa,bの値、すなわち観測値が増えるほど、事後分布のピークは鋭くなっていったのであった。
それはベータ分布の分散の計算結果をみても分散は0に近づいていくのがわかる。
【復習】ベータ分布の分散
$$\operatorname{var}[\mu] =\frac{a b}{(a+b)^2(a+b+1)}$$
このようなベイズ学習の特性は平均的に成り立つ
ベイズ学習の平均的な特性
- データを生成する分布の上で事後平均を平均すると事前平均になる
つまり$$
\mathbb{E}_\theta[\boldsymbol{\theta}]=\mathbb{E}_{\mathcal{D}}\left[\mathbb{E}_{\boldsymbol{\theta}}[\boldsymbol{\theta} \mid \mathcal{D}]\right] $$が言える。 - 事後分散の平均と事後平均の分散を足すと事前分散になる
つまり$$
\operatorname{var}_{\boldsymbol{\theta}}[\boldsymbol{\theta}]=\mathbb{E}_{\mathcal{D}}\left[\operatorname{var}_{\boldsymbol{\theta}}[\boldsymbol{\theta} \mid \mathcal{D}]\right]+\operatorname{var}_{\mathcal{D}}\left[\mathbb{E}_{\boldsymbol{\theta}}[\boldsymbol{\theta} \mid \mathcal{D}]\right] $$が成り立つ。ここで、右辺の第一項は\(\theta\)の事後分散の平均で、第二項は\(\theta\)の事後平均の分散であり正なので、\(\theta\)の事後分散は平均的に、左辺の事前分散より小さくなることがわかる。
ただし
$$
\begin{aligned}
\mathbb{E}_{\boldsymbol{\theta}}[\boldsymbol{\theta}] & \equiv \int p(\boldsymbol{\theta}) \boldsymbol{\theta} \mathrm{d} \boldsymbol{\theta} \\
\mathbb{E}_{\mathcal{D}}\left[\mathbb{E}_{\boldsymbol{\theta}}[\boldsymbol{\theta} \mid \mathcal{D}]\right] & \equiv \int\left\{\int \boldsymbol{\theta} p(\boldsymbol{\theta} \mid \mathcal{D}) \mathrm{d} \boldsymbol{\theta}\right\} p(\mathcal{D}) \mathrm{d} \mathcal{D}
\end{aligned}
$$
カテゴリ分布

今度は、ベルヌーイ分布をより一般的なK次元の離散的な確率分布に拡張してみる
まず、1-of-K符号化法(OneHotエンコーディング)について説明しよう。これは、ある変数が取ることのできる値の数(K)だけ次元を持つベクトルを用いて、その変数の値を表現する方法だ。例えばすごろくのように、変数が6つの値を取ることができるとき、それぞれの値はベクトル \((1,0,0,0,0,0)\)、\((0,1,0,0,0,0)\)、\((0,0,1,0,0,0)\)、\((0,0,0,1,0,0)\) 、\((0,0,0,0,1,0)\)、\((0,0,0,0,0,1)\)で表される。すなわち、値が真である次元だけが1で、他の全ての次元は0である。
この1-of-K符号化法を用いると、K次元ベルヌーイ分布は次のように表現できる。
【定義】K次元ベルヌーイ分布(カテゴリ分布)
$$ p(\mathbf{x} \mid \boldsymbol{\mu})=\prod_{k=1}^K \mu_k^{x_k} $$
ここで、ベクトル \(\mathbf{x}\) は1-of-K符号化法で表現された変数の値で、\(\boldsymbol{\mu} = (\mu_1, \mu_2, ..., \mu_K)\) は各値が真である確率で\(x_k=1\)となる確率をパラメータ\(\mu_k\)と表している。
さて、この分布が確率分布であるためには、全ての可能な \(\mathbf{x}\) に対して、確率を足し合わせたときに1になる必要がある。つまり、
$$ \sum_{\mathbf{x}} p(\mathbf{x} \mid \boldsymbol{\mu})=\sum_{k=1}^K \mu_k=1 $$
でなければならない。
また、\(\mathbf{x}\) の期待値は、全ての可能な \(\mathbf{x}\) に対して、その \(\mathbf{x}\) が出現する確率とその \(\mathbf{x}\) を掛け合わせて足し合わせたものであるから、
$$ \mathbb{E}[\mathbf{x} \mid \boldsymbol{\mu}]=\sum_{\mathbf{x}} p(\mathbf{x} \mid \boldsymbol{\mu}) \mathbf{x}=\left(\mu_1, \ldots, \mu_M\right)^{\mathrm{T}}=\boldsymbol{\mu} $$
となる。
カテゴリ分布の尤度関数を考えてみる
次に、尤度関数について考えてみよう。データ集合 \(\mathcal{D}={x_1, x_2, ..., x_N}\) が与えられたときの尤度関数は、各データ点が独立して生成されると仮定して、各データ点の確率を掛け合わせたものであるから、
$$ p(\mathcal{D} \mid \boldsymbol{\mu})=\prod_{n=1}^N \prod_{k=1}^K \mu_k^{x_{nk}} $$
と表すことができる。
ここで、\(x_{nk}\)はn番目のデータがkという値をとるときに1となり、それ以外の時は0となる。また、\(\mu_k\)はkという値をとる確率を示している。各データ点は独立に生成されると仮定しているため、各データ点の確率は独立に掛け合わされる。
次にこの尤度関数を少し変形してみよう。まず、\(\mu_k^{x_{nk}}\)の部分を考える。これは、データ点nがkという値を取るときに\(\mu_k\)を、取らないときには1を掛けるという操作を表している。これをN個のデータ全てについて行うと、
$$ \prod_{n=1}^N \mu_k^{x_{nk}} = \mu_k^{\left(\sum_n x_{nk}\right)} $$
となる。ここで、\(\sum_n x_{nk}\)は、データ点の中でkという値を取るものの数、つまりkの出現回数を表している。これを\(m_k\)と書くと、
$$ p(\mathcal{D} \mid \boldsymbol{\mu}) = \prod_{k=1}^K \mu_k^{m_k} $$
となる。これは、各値kがデータ集合の中で出現する回数に応じて、その値が出現する確率\(\mu_k\)を掛け合わせる、という操作を表している。
$$
m_k=\sum_n x_{n k}
$$
ベルヌーイ分布と同様、これは十分統計量を表している。
つまりはK次元に拡張された場合の尤度関数は
K次元尤度関数
$$
p(\mathcal{D} \mid \boldsymbol{\mu})=\prod_{n=1}^N \prod_{k=1}^K \mu_k^{x_{n k}}=\prod_{k=1}^K \mu_k^{\left(\sum_n x_{n k}\right)}=\prod_{k=1}^K \mu_k^{m_k} .
$$
尤度関数\(p(\mathcal{D} \mid \boldsymbol{\mu})\)を最大化する$\mu$を求めるために、いつも通り対数をとると計算が楽になる。対数尤度関数\(L(\boldsymbol{\mu})\)は次のように書ける。
$$ L(\boldsymbol{\mu}) = \sum_{k=1}^K m_k \ln \mu_k $$
しかし、ここで\(\mu_k\)の制約を忘れてはいけない。すなわち、\(\mu_k\)の総和が1となる制約がある。その制約を考慮するために、ラグランジュの未定乗数法を用いる。これは、制約付き最適化問題を解くための方法で、制約条件を対象の関数に組み込むというものだ。
具体的には、次のようにラグランジュ関数\(F(\boldsymbol{\mu}, \lambda)\)を定義する。
$$ F(\boldsymbol{\mu}, \lambda) = L(\boldsymbol{\mu}) + \lambda \left(1 - \sum_{k=1}^K \mu_k\right) $$
ここで、\(\lambda\)はラグランジュ乗数と呼ばれる。ラグランジュ関数を最大化すれば、制約付きで尤度関数を最大化できる。ラグランジュ関数を\(\mu_k\)と\(\lambda\)でそれぞれ偏微分して0に等しいと置くと、
$$ \frac{\partial F}{\partial \mu_k} = m_k/\mu_k - \lambda = 0, \quad (1) \\ \frac{\partial F}{\partial \lambda} = 1 - \sum_{k=1}^K \mu_k = 0. \quad (2) $$
メモ
\(\mu_k\)について偏微分すると、最適な\(\mu_k\)の値を直接求めることができるが、ラグランジュ乗数\(\lambda\)についても偏微分する必要がある。なぜなら、\(\lambda\)は制約条件\(\sum_{k=1}^K \mu_k = 1\)を強制するためのパラメータであり、この制約が満たされるように\(\lambda\)を調整する必要があるからだ。
このため、\(\lambda\)について偏微分し、その結果を0に等しいと置くことで、制約条件が満たされる\(\lambda\)の値を求めることができる。そして、この\(\lambda\)の値を用いて最適な\(\mu_k\)の値を求めることができる。
これらの式を解くと、各\(\mu_k\)の最尤推定値\(\mu_k^{\mathrm{ML}}\)が得られる。
まず、式(1)から\(\mu_k\)を求めると、
$$ \mu_k = m_k/\lambda. $$
次に、この\(\mu_k\)を式(2)に代入すると、
$$ 1 = \sum_{k=1}^K (m_k/\lambda) = N/\lambda $$
これから、\(\lambda = N\)と求まる。最後に、この\(\lambda\)を\(\mu_k = m_k/\lambda\)に代入すれば、求める最尤推定値\(\mu_k^{\mathrm{ML}}\)が得られる。
$$ \mu_k^{\mathrm{ML}} = m_k/N $$
これらは、N個の観測値のうち\(x_k=1\)であるものの割合になっている。
多項分布

ベルヌーイ分布から二項分布を考えてみたのとアイデアとしては一緒で、カテゴリ分布における施行をN回繰り返した後のk番目の事象に関する出現回数\(m_k\)について考える。気づいた方もいるかもしれないが、ベルヌーイ分布、二項分布、カテゴリ分布と紹介してきたが、実はこれらの分布はすべてこの二項分布の特殊な場合とみることができる。
【定義】多項分布
パラメータ\(\mu\)と観測値の総数\(N\)が与えられた条件の下で、\(m_1, m_2, \ldots, m_K\)の同時確率を考えたものを多項分布という。つまり
$$
\operatorname{Mult}\left(m_1, m_2, \ldots, m_K \mid \boldsymbol{\mu}, N\right)=\left(\begin{array}{c}
N \\
m_1 m_2 \ldots m_K
\end{array}\right) \prod_{k=1}^K \mu_k^{m_k}
$$
と定義される。ここで正規化係数は、N個の対象を、大きさが\(m_1, m_2, \ldots, m_K\)の\(K\)個のグループに分割する場合の数に相当し
$$
\left(\begin{array}{c}
N \\
m_1 m_2 \ldots m_K
\end{array}\right)=\frac{N !}{m_{1} ! m_{2} ! \ldots m_{K} !}
$$で与えられる
さらに、変数\(m_k\)は
$$
\sum_{k=1}^K m_k=N
$$の制約に従う
多項分布の平均と分散
多項分布の平均と分散に関しては以下のようになる
多項分布の平均と分散
$$
E\left[m_k\right]=N \mu_k
$$
$$
\operatorname{var}\left[m_k\right]=N \mu_k(1-\mu_k)
$$
となり、これは二項分布のものがそのまま使える。理由はが起こらないという事象はひとまとめに扱うことができるからである。これがカテゴリ分布の部分で平均と分散について議論しなかった理由である。
ディリクレ分布
さて、二項分布に対してベータ分布という事前分布を導入したのと同様、多項分布のパラメータ\(\mu_k\)に対する事前分布の族を導入したい。多項分布の形式から、共役分布は次のように書けると考えられる。
$$ p(\boldsymbol{\mu} \mid \boldsymbol{\alpha}) \propto \prod_{k=1}^K \mu_k^{\alpha_k-1} $$
ここで、\(\boldsymbol{\alpha} = (\alpha_1, \alpha_2, ..., \alpha_K)\)は分布のパラメータであり、これは事前分布の「形」を制御する。もちろん\( 0 \leq \mu_k \leq 1 \) かつ \(\sum_k \mu_k=1\)である
この\(\mu_k\)の総和の制約から帰化的に考えると\(K-1\)次元の単体(有界線形多様体)上に制限されて分布することに注意する

三変数\(\mu_1,\mu_2,\mu_3\)上のディレクトリ分布の場合は制約のためにこの赤い正三角形の中に制限される。
この共役分布を正規化すると、以下のようになりこれがディリクレ分布である。
【定義】ディリクレ分布
$$
\operatorname{Dir}(\boldsymbol{\mu} \mid \boldsymbol{\alpha})=\frac{\Gamma\left(\alpha_0\right)}{\Gamma\left(\alpha_1\right) \cdots \Gamma\left(\alpha_K\right)} \prod_{k=1}^K \mu_k^{\alpha_k-1}
$$
ここで、\(\Gamma(x)\)はガンマ関数で、\(\alpha_0\)は\(\alpha_0=\sum_{k=1}^K \alpha_k\)で定義されるものである。
$$
\frac{\Gamma\left(\alpha_0\right)}{\Gamma\left(\alpha_1\right) \cdots \Gamma\left(\alpha_K\right)}
$$この部分がディリクレ分布の正規化項である
パラメータをいろいろ変えてみると単体上のディリクレ分布はその密度の値を変化させる

上の図は、先の三変数の場合の単体(正三角形)を二つの水平軸に合わせ、縦軸に密度の値を表したもので左から\(\left\{\alpha_k\right\}=0.1\)、\(\left\{\alpha_k\right\}=1\)、\(\left\{\alpha_k\right\}=10\)の場合のグラフである。
パラメータ\(\boldsymbol{\alpha}\)の各成分が大きいほど、対応する\(\mu_k\)周りに分布が集中する。つまり、\(\alpha_k\)が大きいと、確率変数が\(k\)番目の値を取る確率が高くなり。逆に、\(\alpha_k\)が小さいと、確率変数が\(k\)番目の値を取る確率が低くなる。
このディリクレ分布を事前分布として、先ほどの多項分布を尤度関数としたものをかけると、パラメータ{\(\mu_k\)}の事後分布は
$$
p(\boldsymbol{\mu} \mid \mathcal{D}, \boldsymbol{\alpha}) \propto p(\mathcal{D} \mid \boldsymbol{\mu}) p(\boldsymbol{\mu} \mid \boldsymbol{\alpha}) \propto \prod_{k=1}^K \mu_k^{\alpha_k+m_k-1} .
$$
となり確かにこの事後分布もディリクレ分布の形式となっており、実際
$$
\begin{aligned}
p(\boldsymbol{\mu} \mid \mathcal{D}, \boldsymbol{\alpha}) & =\operatorname{Dir}(\boldsymbol{\mu} \mid \boldsymbol{\alpha}+\mathbf{m}) \\
& =\frac{\Gamma\left(\alpha_0+N\right)}{\Gamma\left(\alpha_1+m_1\right) \cdots \Gamma\left(\alpha_K+m_K\right)} \prod_{k=1}^K \mu_k^{\alpha_k+m_k-1}
\end{aligned}
$$
このように表示することができる。ここで、\(\mathbf{m}=\left(m_1, \ldots, m_K\right)^{\mathrm{T}}\)である。
つまりディリクレ分布も確かに多項分布の共役事前分布であることを確かめることができた。
まとめ
この記事では離散的な確率分布について数学的な証明から逃げずに解説してきた。さらにそれらをベイズ的に考えるために事前共役となる連続確率分布であるベータ分布とディリクレ分布についても解説したスーパーヘビーな記事だった。