
最近のデータ解析や機械学習の分野で重要な役割を果たす多項式曲線フィッティング。
これは機械学習の基礎の基礎となる内容が詰め込まれており勉強になる。
その基本的な理解を深め、適切なモデル選択がいかに重要かを学ぶために、本記事では多項式曲線フィッティングの定義から過学習を回避する方法までをわかりやすく解説していく。
因みに前回の内容はこちら
-

そもそも機械学習ってなんだ?手書き数字認識でわかる機械学習の種類と分類
昨今AIの隆盛、発展は著しく、AIや機械学習というものに興味がある人も増えていることと思う。 もうすでに組みあがったAIモデルやAIサービスを利用するのも面白いのだが、なぜAIが成り立っているのか、ど ...
続きを見る

多項式曲線フィッティング
回帰問題について考えてみよう。回帰問題とは教師あり学習の一種で、入力ベクトルに対応する連続値を予測するタスクであった。
ここからはこの例を用いて、多くの重要な概念を説明していく。

訓練データ集合(青い点). 横軸は入力変数 x であり,縦軸が予測したい目的変数 t . 緑の曲線は y = sin ( 2 π x ) .
今回の例では、元のデータはsin関数\(\sin(2\pi x)\)から生成されており、その関数値にガウス分布に従う小さなランダムノイズが加えられている。これにより、実際の観測値tが得られる。つまり、真の関数にノイズが加わって、観測データが作られるわけだ。
僕たちの目標は\(\sin(2\pi x)\)を知らない状態、つまりこの青い点だけを観測できる状態で新しい入力ベクトル\(\widehat{x}\)が与えられたときに目標変数\(\widehat{t}\)を予測すること
これは背後にある関数\(\sin(2\pi x)\)を有限個のデータ集合から見つけ出すということと同じことで、汎化させるのがとても難しい。
なぜならば観測データにノイズがのっており、与えられた\(\widehat{x}\)に対する\(\widehat{t}\)の値には不確実性があるからである。
ここで登場するのが確率論で、確率論はそのような不確実性を厳密かつ定量的に表現することができるようになる。さらには決定理論は、確率論を利用して、適切な基準を設けて最適な予測ができるようになる。
それは後々しっかり勉強するとして、今は多項式曲線フィッティングというアプローチを考えてみる。
定義
まず、多項式曲線フィッティングとは、与えられたデータに対して最適な多項式を見つけることだ。具体的には、訓練集合にある観測値xと対応する観測値tを使って、データにうまく適合する多項式を求める。
線形モデルは、入力xとパラメータwを使って、出力tを予測するモデルだ。多項式曲線フィッティングでは、線形モデルを以下のように定義する。
【定義】多項式曲線フィッティング
ここで、Mは多項式の次数で、\(w_j\)はパラメータだ。留意したいのは、この多項式がxの非線形関数であるものの、wについては線形関数であるという点である。
さてこれをどのように具体的に予測するのかだが、ここで登場するのが誤差関数である。
誤差関数は、予測値と実際の観測値との誤差を評価する関数だ。今回は、二乗和誤差関数を使って評価する。
【定義】二乗和誤差

この誤差関数を最小化するパラメータwを求めることで、多項式曲線フィッティングが完成する。パラメータwを求める方法として、最小二乗法が一般的だ。最小二乗法では、誤差関数をwで偏微分し、その値が0になるようなwを求める。
さてこの誤差関数を最小にするwを求めてみる。
誤差関数を最小にする係数wは線形方程式の解として与えられる
二乗和誤差関数を最小にする係数\(\mathbf{w}\)は、線形方程式の解として与えられることを示す。まず、二乗和誤差関数\(E(\mathbf{w})\)を定義する。
$$E(\mathbf{w}) = \frac{1}{2}\sum_{n=1}^N \{ y(x_n, \mathbf{w}) - t_n \}^2$$ここで、\(y(x, \mathbf{w}) = \sum_{j=0}^M w_j x^j\)は多項式モデルである。この誤差関数を最小にする\(\mathbf{w}\)を求めるために、誤差関数を各係数\(w_j\)で偏微分し、その結果が0となるような\(\mathbf{w}\)を見つける。つまり、
$$\frac{\partial E(\mathbf{w})}{\partial w_j} = 0 \hspace{15pt} (j = 0, 1, \cdots, M)$$誤差関数の偏微分を計算する。
$$\frac{\partial E(\mathbf{w})}{\partial w_j} = \frac{\partial}{\partial w_j} \frac{1}{2}\sum_{n=1}^N \{ \sum_{k=0}^M w_k x_n^k - t_n \}^2$$チェーンルール\(h'(x) = f'(g(x)) \cdot g'(x)\)を使って計算する
$$\frac{\partial E(\mathbf{w})}{\partial w_j} = \sum_{n=1}^N \{ \sum_{k=0}^M w_k x_n^k - t_n \} \frac{\partial}{\partial w_j} \{ \sum_{k=0}^M w_k x_n^k - t_n \}$$ \(j \ne k\)のとき、\(\frac{\partial}{\partial w_j}(w_k x_n^k)=0\)なので、 $$\frac{\partial E(\mathbf{w})}{\partial w_j} = \sum_{n=1}^N \{ \sum_{k=0}^M w_k x_n^k - t_n \} x_n^j$$この偏微分が0となるような\(\mathbf{w}\)を求める。
$$\sum_{n=1}^N \{ \sum_{k=0}^M w_k x_n^k - t_n \} x_n^j = 0 \hspace{15pt} (j = 0, 1, \cdots, M)$$この方程式を整理すると、以下の線形方程式が得られる。
$$\sum_{k=0}^M \left( \sum_{n=1}^N x_n^{j+k} \right) w_k = \sum_{n=1}^N t_n x_n^j \hspace{15pt} (j = 0, 1, \cdots, M)$$これは、行列形式で表すことができる。
$$\mathbf{A}\mathbf{w} = \mathbf{b}$$ここで、
$$\mathbf{A} = \left[ \sum_{n=1}^N x_n^{j+k} \right]_{j,k=0}^M$$は\((M+1) \times (M+1)\)の行列、\(\mathbf{w}=(w_0, w_1, \cdots, w_M)^T\)は\((M+1)\)次元のベクトル、\(\mathbf{b} = \left(\sum_{n=1}^N t_n x_n^j\right)_{j=0}^M\)は\((M+1)\)次元のベクトルである。
この線形方程式\(\mathbf{A}\mathbf{w} = \mathbf{b}\)は、二乗和誤差関数\(E(\mathbf{w})\)を最小にする係数\(\mathbf{w}\)を求める問題に対応している。そして、この線形方程式の解は逆行列を使って求めることができる。
$$\mathbf{w} = \mathbf{A}^{-1}\mathbf{b}$$ただし、\(\mathbf{A}^{-1}\)は\(\mathbf{A}\)の逆行列である。この解が存在するためには、\(\mathbf{A}\)が正則でなければならない(すなわち、\(\mathbf{A}\)の行列式が0でない)。この条件が満たされている場合、上記の式で誤差関数を最小にする\(\mathbf{w}\)を求めることができる。
以上から、二乗和誤差関数を最小にする係数\(\mathbf{w}\)は、線形方程式の解として与えられることが示された。この結果を用いて、与えられたデータに適合する多項式モデルを求めることができる。
モデル選択(モデル比較)
あとは多項式の次数Mを決めるという問題がある。この問題はモデル選択(model selection)や、モデル比較(model comparison)と呼ばれる。
先の回帰問題について、Mを動かしたときに\(\sin(2\pi x)\)に最も近づくのは一体どれなのか??
 | 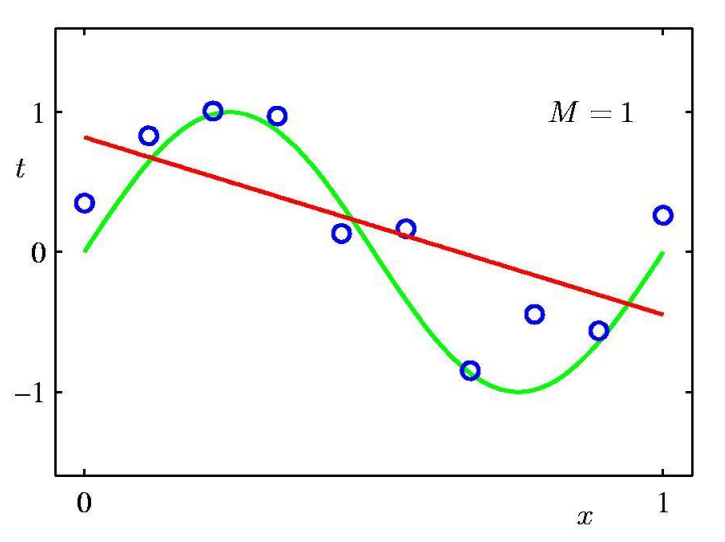 |
 |  |
定数の場合(M=0)と一次の場合(線形回帰)(M=1)は正味微妙な感じで、三次の場合(M=3)が最も綺麗に\(\sin(2\pi x)\)に近似しているように見える。
直感的には次数が高い方が係数wの数が増えるからよく近似できる気がするのだが、これだと青い点(訓練データ)には適合できているが\(\sin(2\pi x)\)の表現としては明らかにおかしい。
つまりはデータに過度に適合しすぎるため、新しいデータに対する予測性能が低下してしまっている。これを「過学習」という。
過学習を防ぐために、汎化性能を評価する指標が必要である。平均二乗平方根誤差(RMSE: Root Mean Squared Error)は、そのような指標の一つである。RMSEは、予測と実際の値の差の二乗平均を平方根したもので、次のように定義される。
【定義】平均二乗平方根誤差
ここでΣ以降は先の二乗和誤差を表しており、つまりここでの\(w\)はすでに二乗和誤差が最小になるものを既に選んでいるものである。混同を避けるために\(w^{\ast }\)と書くと
$$E_{RMS}=\sqrt{2E\left( W^{\ast }\right) /N}$$この式に関してはそんなに難しいものじゃなくて、まずNで割るのはサイズ(N)が異なるデータ集合ほ比較するため、平方根をとるのは\(E_{RMS}\)を目的変数tと同じ単位にするためである。
さて、では次数ごとの訓練データとテストデータの誤差を見てみよう

Mが0から大きくなると、訓練データ(青)の誤差は単調に減っていく。しかし、テストデータ(赤)の誤差は、M=8までは誤差が減るもののM=9の時は急激に大きくなる。
M=9の場合では、係数の数が\(w_{0},\ldots ,w_{9}\)の10個なので、多項式の自由度が10となり、訓練集合の10個のデータにちょうど当てはめることができてしまう。
Mが大きくなると自由度が高くなるため、複雑なモデルでも柔軟に処理できるようになるが、自由度が高すぎると訓練データのノイズに引きずられて、係数\(w_j\)の値が非常に大きな値を取るようになる。この現象を過学習という。

過学習を回避するには
過学習の問題を避けるには
- データ数を増やす
- モデルの複雑さを減らす
- ベイズ的アプローチをとる
- 正則化を行う
などがある。ひとつひとつ見ていこう。
データ数を増やす
実際にモデルの次数を\(M=9\)に固定して、データ集合のサイズ(N)を増やしてみよう。

N=15(左)とN=100(右)のデータ点に対して最小二乗法で当てはめた結果、データのサイズを増やすとフィッティングの性能が高くなっているのが分かる。つまり、データ数が多いほど、モデルの汎化性能が向上し過学習が防がれる。
これは相対的に考えれば、データのサイズ(N)に対して、多項式の自由度を減らしていると考えることもできるので、、
モデルの複雑さを減らす
今回の場合、多項式の次数Mを減らすことで過学習を抑制する。これは先ほどのモデル比較で見た通りである。
ベイズ的アプローチをとる
モデルのパラメータに確率分布を設定し、データからその分布を更新する。これによって不確実性を考慮し、過学習を抑制できる。
これは後ほど詳しくやるらしいので、一旦この段階では、ベイズモデルを使えばパラメータ数がデータの点の数を越えても問題ないということを頭の片隅に入れておこう。
正則化を行う(L1/L2正則化)
これは、誤差関数にペナルティ項を与えることで、過学習を防ごうとするもので、L1正則化(LASSO回帰)やL2正則化(Ridge回帰)などがある。
L1正則化(LASSO回帰)
ここで、\(\lambda\)は正則化係数で、\(|w_j|\)はパラメータの絶対値である。
L1正則化は、モデルにおいて重要度の低い特徴量の影響力が極力削減された状態を導く傾向があり、特徴選択に役立つ。
L2正則化(Ridge回帰)
$$ E_{L2}(w) = \frac{1}{2}\sum_{n=1}^{N}(y(x_n, w)-t_n)^2 + \frac{\lambda}{2}\sum_{j=0}^{M}w_j^2 $$
ここで、\(\lambda\)は正則化係数で、\(w_j^2\)はパラメータの二乗である。
L2正則化は、パラメータの値を小さく抑える効果があり、過学習を防ぐ。L1正則化よりも精度が高い傾向がある。
式に登場する\(\lambda\)は重みづけのパラメータで、「二乗誤差を小さくする」ことと「データを単純化する」ことの、どちらをどの程度優先するかを制御できる。\(\lambda\)が大きければ大きいほど\(\sum_{j=0}^{M}w_j^2\)を小さくすることが優先される。
今回はL2正則化の方を使って過学習を抑えることを試みてみる。
と、その前にL2正則化した場合でも誤差関数を最小にする解は完全に閉じた解で求まるのか考えてみよう。
L2正則化された二乗和誤差関数を最小にする係数wが満たす線形方程式を書き下そう
与えられた式に従って、二乗和誤差関数を再計算する。
$$ \tilde{E}(w) = \frac{1}{2}\sum_{n=1}^{N}(y(x_n, w)-t_n)^2 + \frac{\lambda}{2}|w|^2 $$
ここで、\(y(x_n, w)\)はモデルの予測値、\(t_n\)は実際の目的変数の値、\(N\)はサンプル数、\(|w|^2\)はパラメータのL2ノルム、\(\lambda\)は正則化係数である。
$$ \tilde{E}(w) = \frac{1}{2}\sum_{n=1}^{N}\Bigl(\sum_{j=0}^{M}w_jx_n^j - t_n\Bigr)^2 + \frac{\lambda}{2}|w|^2 $$
ここで、\(x_n\)は入力データ、\(t_n\)は目的変数の値、\(N\)はサンプル数、\(M\)は多項式の次数、\(w_j\)はモデルのパラメータ、\(|w|^2\)はパラメータのL2ノルム、\(\lambda\)は正則化係数である。
この誤差関数を最小化するパラメータ\(w\)を求めるため、\(\tilde{E}(w)\)を\(w_k\)で微分した式を0になるように設定する。
$$ \frac{\partial \tilde{E}(w)}{\partial w_k} = \sum_{n=1}^{N}\Bigl(\sum_{j=0}^{M}w_jx_n^j - t_n\Bigr)x_n^k + \lambda w_k = 0 $$ (1)(1)式を行列で表現するため、以下のように設定する。
$$X = \begin{bmatrix}x_1^0 & x_1^1 & \cdots & x_1^M \\ x_2^0 & x_2^1 & \cdots & x_2^M \\ \vdots & \vdots & \ddots & \vdots \\ x_N^0 & x_N^1 & \cdots & x_N^M \end{bmatrix}$$ ,
$$w = \begin{bmatrix}w_0 \\ w_1 \\ \vdots \\ w_M \end{bmatrix} , t = \begin{bmatrix}t_1 \\ t_2 \\ \vdots \\ t_N \end{bmatrix}$$
こうすると、(1)式は次のように表現できる。
$$ X^T(Xw - t) + \lambda w = 0 $$ (2)この式を\(w\)について解くと、閉じた形式の解が得られる。
$$ (X^TX + \lambda I)w = X^Tt $$ (3)ここで、\(I\)は単位行列である。この(3)式を解くことで、正則化された二乗和誤差関数が最小となるパラメータ\(w\)が求まる。
以上で、与えられた二乗和誤差関数に対して閉じた形式の解を求めることができた。
なお、閉じた解とは、数学的な問題や方程式の解が有限回の演算によって明示的に表現できる形で求められる解のことである。
さて、正則化していても最小値にする解が得られることが分かったところで実際に正則化を取り入れて訓練データから多項式フィッティングを行ってみよう

左が\(\lambda =e^{-18}\)としたときのもの、右が\(\lambda =1\)
\(\lambda =e^{-18}\)の方はM=9なのに先ほどと違っていい感じにフィットしている。過学習が改善されている。ただこの\(\lambda\)の数値によってかなり違いがあって

この\(\lambda =e^{-\infty }\)というのは正則化していない状態と同じであることに注意しておくと、\(\lambda =e^{-18}\)というのは正則化されていない状態とくらべてwの発散が抑えられている。
つまり\(\lambda\)というのはすごく重要なパラメータで「訓練データとのズレ」と「複雑なモデル」どちらを減らすことを重視するかということを決定づける。
\(\lambda\)が小さければ小さいほど、訓練データとのズレを小さくすることを重視するようになる。よって過学習を起こしやすい傾向がある。実際\(\lambda =e^{-\infty }\)つまり、\(\lambda =0\)となるときは実際過学習となっていた。
反対に、\(\lambda\)が大きければ大きいほど、単純なモデルをつくることを重視するようになる。上のグラフに見るように\(\lambda =1\)のときにはほぼ直線のようになっていた。
つまるところ、\(\lambda\)は大きすぎてもダメだし小さすぎてもだめ。適度なところがいいという結論なのだが。
どうしたらよい値を定めることができるのか?\(\lambda\)だけではない。多項式の次数Mについてもどの程度がいいのか決めなければならない。
確認用集合(validation set)の用意
単純な解決方法として、確認用集合を用意することがある。つまりは訓練集合とは別にモデルのパラメータをより良いものに調整するためののデータセットを用意しておくということだ。
これはあくまでモデルの汎化性能を上げるためのパラメータ調整するためのデータセットで先まで扱っていた「テストデータ」とは区別される。
まとめ
本記事では、多項式曲線フィッティングの定義、誤差関数の最小化に関する演習問題、モデル選択や過学習の回避方法について解説した。過学習を防ぐためにデータ数を増やす、モデルの複雑さを減らす、ベイズ的アプローチを取る、正則化を行うなどの方法が挙げられた。また、正則化に関する演習問題と、確認用集合の用意についても触れた。データ解析や機械学習を学ぶ上で、本記事が理解の助けとなれば幸いである。
次回からは確率論を使ってパターン認識における問題をとくための原理的なアプローチを探っていく
-
機械学習で使う確率論の基礎、確率の加法・乗法定理、ベイズの定理など
今回の記事は確率論の基礎を語る。 パターン認識の分野において非常に重要な概念が不確実性である。それは計測ノイズやデータ集合のサイズが有限だからであった。 確率論によって不確実性に関する定量化と操作をす ...
続きを見る
